Тестирование с помощью JUnit
Юнит тестирование - тема для бесконечных споров. Сам я считаю написание тестов неотъемлемой частью процесса разработки. Они помогают быстрее писать код, повышают его качество. Можно выделить два подхода к разработке программ. Первый - реализовать задачу полностью, потом проверять и исправлять ошибки (либо особенно не проверяя отдать команде тестирования). Второй - проверять функционал по ходу разработки и, когда все компоненты реализованы, получить почти готовое решение. Программисты шутят, что если запустил программу в первый раз и она работает, то здесь какой-то подвох. Тесты необходимы, чтобы переходить от первого подхода ко второму.
Я использую следующий принцип: есть несколько ситуаций, когда тесты полезны и помогают в разработке. Когда я встречаюсь с такой ситуацией, то обычно даже первым делом пишу не код, а тест к нему, либо параллельно. Если же хорошего способа проверить код юнит тестом я не вижу, то не трачу слишком много времени, чтобы его придумать. Со временем такой "список рецептов" пополняется. Конечно, до тестового покрытия 80%, которое статические анализаторы считают минимальным пороговым значением на пятерку, такой подход не дотягивает. Чаще получается что-то в коридоре от 40 до 60 процентов. Чтобы достичь 80% нужно изучать отчёт о покрытии кода и писать часто неестественные и ненужные тесты. Я встречал getter-setter тесты, которые с помощью reflection вызывают get/set по всем полям класса и сравнивают результат.
В то же время всё относительно. Если бы я разрабатывал криптографические алгоритмы или ядро блокчейн платформы или платежной системы, то ни на какие компромиссы и допущения идти было бы нельзя. В таком критическом коде тесты должны проверять все строчки кода, все возможные сценарии исполнения и входные параметры. Но среднестатистический проект - как правило обычное корпоративное приложение наподобие внутренней системы управления заказами.
Далее разберу несколько типовых сценариев применения юнит тестов.
Алгоритмы
Сортировка
Реализация алгоритмов, пожалуй, самый яркий пример пользы и даже необходимости юнит тестов. У алгоритмов просто нет пользовательского интерфейса, чтобы проверять их другим способом. Разве что вводить входные параметры через терминал и распечатывать результат, визуально сравнивая его с ожидаемым.
Справедливо будет отметить, что теория тестирования - сложная наука, которая является полноценным направлением в информационных технологиях. Разрабатываются модели, формулируются и доказываются теоремы с целью математически гарантировать корректность работы алгоритма. То есть тест не просто проверяет несколько основных сценариев работы алгоритма, вместо этого он гарантирует правильность реализации для любых входных параметров. Подобные исследования имеют место в системах, в которых ошибки в коде могут привести к катастрофам. Здесь же я рассматриваю простые практические случаи, в которых тест как правило проще реализации, но при этом позволяет исключить очень много ошибок.
Для начала напишем тест, который проверяет алгоритм сортировки. В репозитории это класс CollectionSortTest.
Сравниваем длину; проверяем, что каждый элемент не больше следующего; суммируем все элементы до и после. Всё!
Ценность такого теста - простота. Нам не требуются сложные алгоритмы, не требуется много времени на написание
и не нужно ничего знать о конкретной реализации.
Да, возможно придумать алгоритм, который изменит данные при сортировке, но пройдёт тест.
Однако случайно допустить подобную ошибку при реализации алгоритма сортировки практически невозможно.
void checkArraySortedCorrectly(long[] original, long[] sorted) {
long sumOriginal = LongStream.of(original).sum();
long sumSorted = LongStream.of(sorted).sum();
assertEquals(original.length, sorted.length);
assertEquals(sumOriginal, sumSorted);
for (int i = 1; i < sorted.length; i++) {
assertTrue(sorted[i-1] <= sorted[i]);
}
} @RepeatedTest(100)
void testArraysNotSorted() {
long[] original = randomLongArray(100_000);
long[] sorted = copy(original);
Arrays.sort(sorted);
sorted[1] = sorted[0];//имитируем ошибку в результате
assertThrows(AssertionFailedError.class, () -> {
checkArraySortedCorrectly(original, sorted);
});
}
@RepeatedTest(100)
void testArraysSort() {
long[] original = randomLongArray(100_000);
long[] sorted = copy(original);
Arrays.sort(sorted);
checkArraySortedCorrectly(original, sorted);
}
Имеет смысл при тестировании алгоритмов проверить граничные случаи: пустой массив, массив из одного элемента, уже отсортированный, обратно отсортированный, массив одинаковых элементов. А после - много раз проверить на большом наборе случайных данных.
Код Хэмминга
Код Хэмминга - один из алгоритмов избыточного кодирования данных для передачи через ненадежные каналы, подверженные случайным ошибкам. Позволяет исправлять ошибку в передаче одного бита входного сообщения, требуя порядка log(n) бит избыточной информации. Алгоритм относительно сложный и я здесь не привожу его описания. Предлагаю написать тесты, даже не изучая сам алгоритм, а лишь требования, то есть задачу, которую он решает. Такой подход к тестированию называют методом чёрного ящика. Когда реализация доступна, то имеем метод белого ящика.
Реализация будет работать с последовательностью бит, кратной байту, хотя оригинальный алгоритм этого не требует.
Для декодирования требуется знать размер исходного сообщения, потому что по закодированному сообщению. определить его однозначно нельзя.
Зафиксируем интерфейс и можно приступать к тесту.
byte[] encode(byte[] source);
byte[] decode(byte[] encoded, int sourceSizeBytes);
Вот что у меня получилось.
Я реализовал два рандомизированных теста - первый проверяет работу алгоритма без искажения данных, второй при инверсии одного случайного бита.
@RepeatedTest(100)
void encodeDecodeNoBrokenBits() {
int length = random.nextInt(10_000) + 1;
byte[] original = randomByteArray(length);
byte[] thereAndBackAgain = encoder.decode(encoder.encode(original), original.length);
assertArrayEquals(original, thereAndBackAgain);
}
@RepeatedTest(100)
void encodeDecodeRandomBrokenBits() {
int length = random.nextInt(10_000) + 1;
byte[] original = randomByteArray(length);
byte[] encoded = encoder.encode(original);
invertRandomBit(encoded);
byte[] thereAndBackAgain = encoder.decode(encoded, original.length);
assertArrayEquals(original, thereAndBackAgain);
} @RepeatedTest(100)
void encodeDecodeRandom2BrokenBits() {
int length = random.nextInt(10_000) + 1;
byte[] original = randomByteArray(length);
byte[] encoded = encoder.encode(original);
setBit(encoded, 0, bitAt(encoded, 0) ^ 1);
setBit(encoded, 1, bitAt(encoded, 1) ^ 1);
byte[] thereAndBackAgain = encoder.decode(encoded, original.length);
assertThrows(AssertionFailedError.class, () -> {
assertArrayEquals(original, thereAndBackAgain);
});
}
Как обычно, полная версия кода есть в репозитории.. Не скажу, что код идеальный, потому что, как говорил мой коллега, "код бывает только плохой и ещё не написанный". На случай, если кто-то будет изучать сам алгоритм и реализовывать его, отмечу несколько недочётов, которые допущены в реализациях, которые нашлись первыми по запросу "hamming code implementation java". Эти недочёты не связаны с работой алгоритма, а только со стилем написания кода и используемыми приемами. Когда перед интервью вас просят решить тестовую задачу, проверяющий в первую очередь оценивает общее качество кода, а уже во вторую - правильность алгоритма. Итак, что мне не понравилось в большинстве реализаций:
- Манипулирование битами с помощью строковых операций (например, Integer.toBinaryString(k), charAt). Это крайне неэффективно и я считаю грубой ошибкой. Такие операции можно использовать в тестах, чтобы код теста был более выразительным и читаемым.
- Упрощение задачи. Вместо заморочек с битовыми операциями, вводится массив int[], в котором каждый элемент соответствует одному биту. Потребление памяти в 32 раза больше оптимального.
- Смешивание всего в одну кучу - один большой метод main, который реализует алгоритм, запрашивает входные данные, печатает промежуточные шаги, печатает результат и т.д. Такой код на один раз, чтобы разобраться с алгоритмом.
Базы данных
Теперь рассмотрим более привычные применения юнит тестов. На мой взгляд, самый частый и хорошо отработанный случай - тестирование операций с реляционными базами данных. В случае с алгоритмами ошибки связаны непосредственно с кодированием: это неправильная реализация, граничные случаи, ошибки переполнения и так далее. В случае интеграции и обращения к другим системам и сервисам многое не проверяется на этапе компиляции. Необходимо довести приложение до рабочего состояния и смоделировать какой-то сценарий использования, чтобы проверить работу, например, сброса пароля.
Существуют реализации СУБД, которые инициализируются вместе с приложением и хранят данные в памяти (in memory). Наиболее популярные среди них - это H2 и HSQLDB (Hyper SQL Database). Обе поддерживают синтаксис большинства полноразмерных СУБД: Oracle, PostgreSQL, MS SQL Server, MySQL с известными ограничениями. В примере используется H2. В приложении во время запуска теста мы подменяем соединение с основной базой данных (или DataSource) на соединение с H2, далее выполняются скрипты инициализации (CREATE TABLE, INSERT INTO, ...). Также схему можно инициализировать автоматически с помощью hibernate auto ddl, но лучше иметь явные скрипты.
Сильная связанность и слабая конфигурируемость системы может быть препятствием в реализации тестов, но при следовании современным подходам (Spring Boot - яркий пример) достаточно создать тестовый профиль (Profile) либо иметь отдельную конфигурацию в test/resources/application.yml. Сам тест обычно представляет из себя последовательность вызовов компонента доступа к БД (DAO, Data Access Object), которые по сути проверяют друг друга. Например, сохранили новый объект, вычитали из базы, проверили, что он добавился и что сгенерировался идентификатор, потому удалили и проверили, что база пустая. Но неявно мы проверяем намного больше. Во-первых, правильность скриптов и аннотаций JPA. Во-вторых, преобразования отдельных типов данных, таких как LocalDate, Enum. В третьих, настройки транзакций (hibernate для сохранения всегда требует активную транзакцию). В четвёртых, проверяем саму конфигурацию контейнероа (Spring, J2EE). Всё это иначе потребовало бы собирать приложение и запускать его на сервере приложений (tomcat, jetty, weblogic).
Примеры я возьму из поста про таймзоны (Код примера.).
Там я показывал, как избежать смещения времени при работе с БД.
Сначала заменяем datasource на H2.
#test/resources/application.yml
spring:
datasource:
url: jdbc:h2:mem:meetings;MODE=Oracle
driverClassName: org.h2.Driver
username: sa
password: password
platform: org.hibernate.dialect.H2Dialect @SpringBootTest
@DirtiesContext(classMode = DirtiesContext.ClassMode.AFTER_EACH_TEST_METHOD)
@ActiveProfiles(profiles = {"test"})
class MeetingDaoTest {
@Autowired
MeetingDaoJdbcTemplateDaoImpl meetingDaoJdbcTemplateDao;
@Autowired
MeetingDaoSpringDataJpa meetingDaoSpringDataJpa;
@Autowired
EntityManager entityManager; @Test
void testAddFindJpa() {
MeetingDto now = new MeetingDto(null, "jpa now", new Date(), OffsetDateTime.now());
meetingDaoSpringDataJpa.add(now);
TimeZone.setDefault(TimeZone.getTimeZone("Europe/Moscow"));
DateTimeUtils.resetCalendar();
//should return 2: one from schema.sql and one here
List<> meetings = meetingDaoSpringDataJpa.findAllActual();
assertEquals(2, meetings.size());
assertMillisDiffWithNowisSmall(meetings.get(0).getMeetingTimeDate().getTime());
assertMillisDiffWithNowisSmall(meetings.get(1).getMeetingTimeOffsetDateTime().toInstant().toEpochMilli());
}
void assertMillisDiffWithNowisSmall(long epochMillis) {
assertTrue(Math.abs(System.currentTimeMillis() - epochMillis) < 5 * 60 * 1000);
}
В общем, если в приложении происходит работа с реляционными СУБД, то подобные тесты, пожалуй, занимают первое место по полезности. В унаследованном коде с большим количеством зависимостей можно поступить так: выделить классы и интерфейсы для работы с базами данных, оставив только зависимость на DataSource. После этого вместо инициализации приложения целиком (@SpringBootTest или корневой applicationContext.xml), создаём небольшую конфигурацию в тестах, включая в неё только DAO и Embedded Data Source.
REST сервисы
Типичный REST сервис вычитывает данные из базы данных, конвертирует в JSON и отправляет по протоколу HTTP тому, что его вызвал. Поэтому для его тестирования необходимо инициализировать Embedded базу данных, но дополнительно нужно инициализировать embedded web server. Если проект только что создан c помощью Spring Boot Initializer, то это делается легко. Однако когда появляются дополнительные настройки аутентификации, самого сервера либо используется Weblogic, не имеющий embedded реализации, то настраивать такие тесты становится чересчур затратно в сравнении с их пользой. В этом случае, возможно, от юнит тестов стоит отказаться в пользу интеграционных тестов, которые будут подключаться к полностью рабочей среде и выполнять различные HTTP запросы.
Если же таких проблем нет, то с помощью юнит тестирования можно проверять такие вещи, как: конвертацию параметров и тела запроса;
HTTP коды ответа, особенно в случае исключений; логику работы контроллеров, если она имеет место.
Сервер во время теста использует случайный порт, а запросы можно выполнять разными способами, которые отличаются в основном синтаксисом: RestAssured, RestTemplate, WebMvc.
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
@DirtiesContext(classMode = DirtiesContext.ClassMode.AFTER_EACH_TEST_METHOD)
class MeetingRestServiceTest {
@LocalServerPort
private int port;
@Autowired
private TestRestTemplate restTemplate;
@Test
public void testGetActual() throws Exception {
ResponseEntity<MeetingDto[]> actual =
restTemplate.getForEntity("http://localhost:" + port + "/api/meeting/actual", MeetingDto[].class);
assertNotNull(actual);
assertNotNull(actual.getBody());
assertEquals(HttpStatus.OK, actual.getStatusCode());
}
Почтовые отправления
Отправлять email сообщения из Java довольно просто: требуется лишь знать хост и порт почтового сервера, возможно ещё информацию для аутентификации. Но работа с полноценным сервером, который отправляет письма реальным пользователям неудобна и опасна. В качестве примера будем отправлять сообщение об исключении, возникшем на сервере вместе со стектрейсом. Эдакий вариант кустарного мониторинга, который периодически применяется в условиях ограниченных ресурсов. Код примеров.
Нам понадобится библиотека GreenMail, реализующая простой SMTP сервер в памяти.
http://www.icegreen.com/greenmail/#
Инициализация почти тривиальна - передаём хост, порт, включаем сервер перед каждым тестом и выключаем в конце.
Есть вариант использовать JUnit 4 Rule, но я буду по максимуму переходить на использование JUnit 5.
GreenMail greenMail;
ServerSetup[] serverSetups = new ServerSetup[]{new ServerSetup(2525, "localhost", "smtp")};
@BeforeEach
public void beforeEach() {
greenMail = new GreenMail(serverSetups);
greenMail.start();
}
@AfterEach
public void afterEach() {
greenMail.stop();
} @Test
void testReportError() throws MessagingException, IOException {
try {
throw new RuntimeException("sample error message");
} catch(Exception e) {
mailSenderService.reportError(e);
}
MimeMessage[] messages = greenMail.getReceivedMessages();
//4 recipients -> 4 emails
assertEquals(4, greenMail.getReceivedMessages().length);
assertEquals("Server status update", messages[0].getSubject());
assertTrue(messages[0].getContent() instanceof MimeMultipart);
MimeMultipart mp = (MimeMultipart) messages[0].getContent();
assertEquals(2, mp.getCount());
assertTrue(GreenMailUtil.getBody(mp.getBodyPart(0)).contains("sample error message"));
assertTrue(GreenMailUtil.getBody(mp.getBodyPart(1)).contains("java.lang.RuntimeException"));
}
При работе с email на многих проектах возникает путаница в тестовой среде (integration, UAT) в случае работы с реальным SMTP сервером. Дело в том, что данные о пользователях часто импортируются с продакшена, а поэтому мы легко можем с локальной машины или UAT сервера отправить важный отчёт, например, директору. Поэтому вводятся всевозможные настройки, кому отправлять можно, кому нельзя. Иногда в коде вводятся условия отправлять письмо или печатать в лог. Могут использоваться whitelist/blacklist получателей письма. Получается очень трудозатратно и неинтересно.
Чтобы избежать этих проблем можно использовать локальные почтовые сервера с веб или десктоп интерфейсом. Тогда мы сможем отправлять письма в тестовой среде так же, как и на продакшене, но просматривать полученные письма будем в общем интерфейсе, доступ в который разрешён командам разработки и тестирования. На локальной машине я пользуюсь FakeSMTP. На UNIX сервере - Mailcatcher. GreenMail судя по всему тоже можно использовать для этих целей, но это выглядит чуть сложнее. Если поменять порт в настройках на 25 и запустить тест ещё раз с включенным сервером FakeSMTP, получаем такой результат:
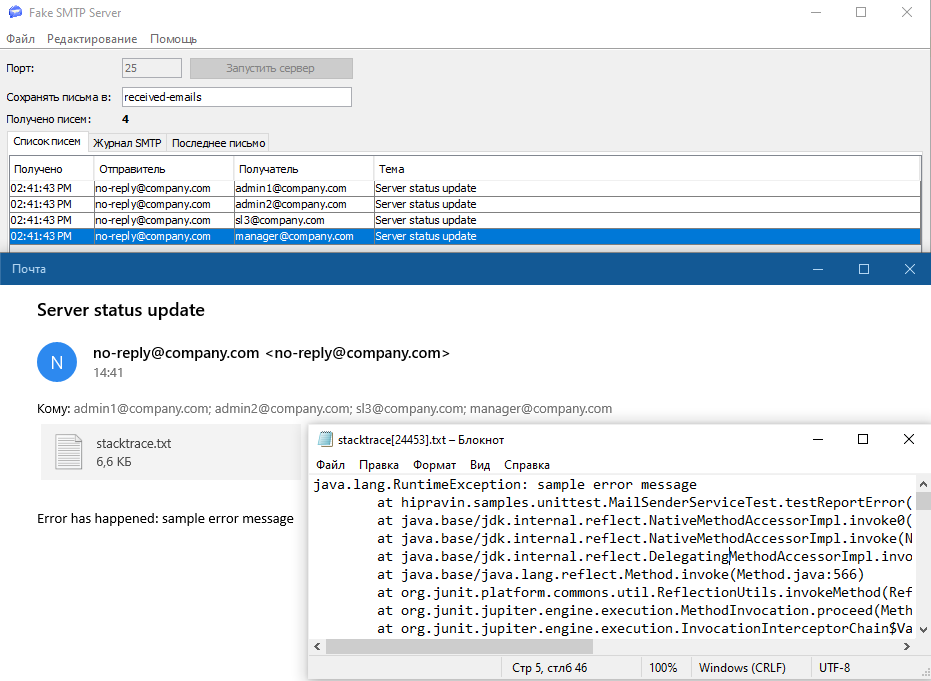
Заключение
Кроме вышеперечисленных, существуют embedded реализации для LDAP, MongoDB, AMQP и многого другого. Такое развитие технологий позволяет создать тестовую конфигурацию в памяти почти для любого приложения и проверять код не выходя из IDE. При хорошем покрытии ручное тестирование применяется к почти работающему приложению с, разве что, небольшими недочётами. Но юнит тесты не заменят ручное тестирование на полностью настроенном окружении и даже не заменят авто тестрование (Selenium, Cucumber и т.д.), а лишь дополнят процесс разработки.