Профилирование в VisualVM
Производительность приложений относительна. Нельзя сказать, что что-то работает быстро или медленно, не сравнивая с другими приложениями или аналогичной ситуацией в прошлом. Вот страница загружается пять секунд - вроде медленно. Но она всегда так загружается - тогда нормально, ожидаемо. А если раньше на это уходило две минуты, тогда можно сказать, что теперь практически мгновенно. Или же в нашем мессенджере сообщения доходят за одну секунду, а в Wazzup'e за 50-100 миллисекунд, то при прочих равных у нас тормоза.
К чему это я? Периодически программисту в работе попадаются задачи вида "Проблемы с производительностью в сценарии X" или "Страница Y медленно загружается". Хуже всего что-то вроде "Улучшить производительность фичи Z". Во всех таких случаях плохо отсутствие конкретики и деталей, и их обычно приходится уточнять перед тем, как можно будет что-то менять в программе.
Может оказаться, что страница так долго загружалась всегда, и это следует из дизайна системы, и чтобы ускорить придётся переделывать всё с нуля. Может быть наоборот, что до последнего релиза всё летало, и тогда вероятна ошибка в коде, которая привела к деградации производительности. Возможно, с ростом нагрузки или количества пользователей какие-то процессы стали работать медленнее по понятным причинам, но требуется обеспечить производительность как раньше, чтобы, например, пользователь не замечал пауз и подгрузок. Если мы выяснили предысторию задачи и чётко понимаем требования, то можно приступать к исследованию и решению проблемы.
В этом посте я покажу простой способ профилировать приложение, запущенное на локальной машине при помощи VisualVM. Цель профилирования - найти фактически самый долгий этап обработки данных. Альтернативный подход - изучать производительность по отладочной печати и логам, но это неудобно и неэффективно. Так приходится поступать с проблемами, которые возникают только на продакшене и решить их никак не удаётся. Но чаще даже в этом случае разумнее потратить силы на воспроизведение проблемы локально (моделируя нагрузку или объём данных продакшена).
Бывает, что в коде очевидно то место, тот метод или запрос к базе данных, который работает медленно. Это может быть обманчивое впечатление! В моей практике была ситуация, когда страница загружалась 35 секунд, и коллега нашёл и починил очевидную проблему в коде, кажется это были множественные запросы к базе данных, когда можно было обойтись одним. Но после фикса страница стала грузиться за рекордные... 30 секунд! Всё это время уходило на рендеринг в браузере, связанный с плохой работой с коллекциями и используемой библиотекой в javascript. То есть не проводя замеров, как бы ни было очевидно улучшение, оно может незначительно повлиять на итоговую производительность.
Код примера. В качестве исследуемого приложения я рассмотрю сервис, который вызывает различные операции, математические функции, работу со строками и файлами. Эти операции не делают ничего полезного, но разделены по методам и мы сможем сравнить, насколько одни типовые операции быстрее или медленнее других. Это полезно, чтобы не экономить на спичках. Например, если у нас в программе есть вызов к базе данных, то не имеет смысла заменять целочисленное деление на 2 на сдвиг вправо на один бит, делая код менее читаемым (val / 2 -> val >> 1), хотя битовые операции и намного эффективнее деления.
Далее - по шагам.
-
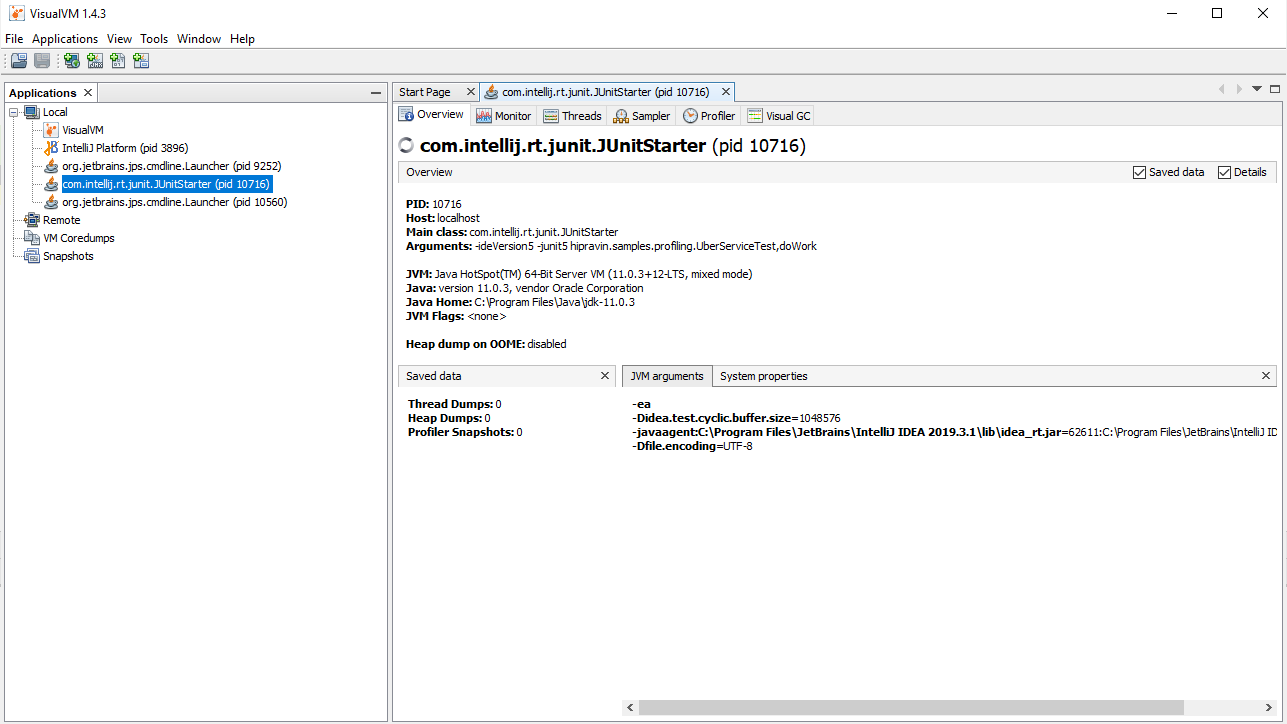
Запускаем VisualVM, потом запускаем тест UberServiceTest. Находим в VisualVM в левой панели JunitStarter и открываем двойным щелчком.
-
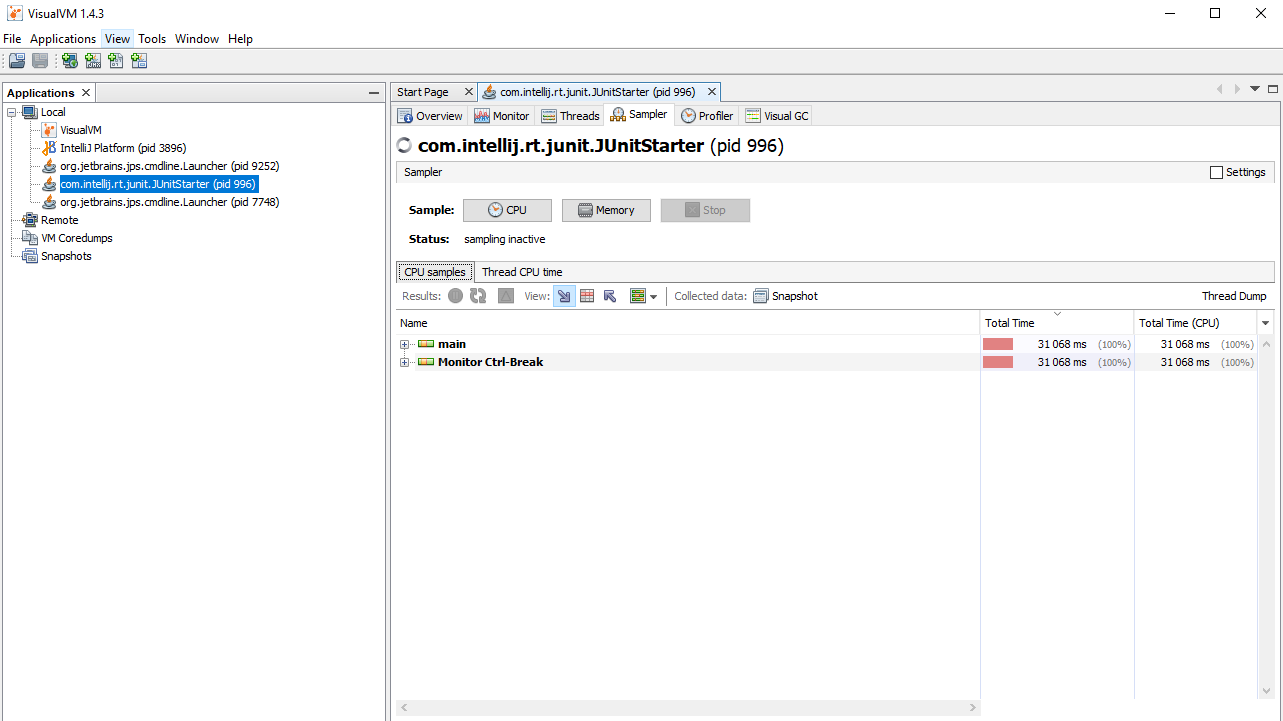
Преходим на вкладку Sampler, нажимаем на кнопку CPU и далее воспроизводим бизнес сценарий, который мы исследуем. В нашем случае просто ждём секунд тридцать.
Потом нажимаем Stop и также останавливаем тест, запущенный в IDE.
- Теперь нажимаем на Snapshot. Далее нужно найти главный поток исполнения, в котором производились все времязатратные операции. Сейчас потоков всего два: main и вспомогательный. В Web приложении их будет не менее десяти - двадцати и придётся искать нужный по имени либо перебирая все по очереди. По дереву вызовов мы должны узнать нужный поток - оно будет содержать классы и методы из пакета приложения, а не только встроенные и библиотечные вызовы.
-
Раскрываем ветку 'main', пока не доберемся до вызовов методов do*.
Видим, что метод doFiles в 20-30 раз медленнее doStrings и doCollections, а остальные методы даже не попали в список.
public static void doWork() throws IOException { int iterations = 100_000; doBinary(iterations); doBinaryString(iterations); doMathPlusMul(iterations); doMathDivide(iterations); doMathLog(iterations); doMathSin(iterations); doCollections(iterations); doStrings(iterations); doMathAsin(iterations); doFiles(iterations); } public static void doCollections(int iterations) { List<Long> values = Stream.generate(r::nextLong).limit(10000).collect(Collectors.toList()); for (int i = 0; i < iterations; i++) { values.contains(0); } } public static void doStrings(int iterations) { String s = Stream.generate(() -> "abcdef").limit(100).collect(Collectors.joining()); String r; for (int i = 0; i < iterations; i++) { r = s.replaceAll("a", "b"); } } public static void doFiles(int iterations) throws IOException { String s = Stream.generate(() -> "abcdef").limit(100).collect(Collectors.joining()); File f = File.createTempFile("hipravin-sample-temp", null); Files.write(f.toPath(), Collections.singletonList(s), StandardCharsets.UTF_8); String r; for (int i = 0; i < iterations; i++) { r = Files.readString(f.toPath()); } f.delete(); }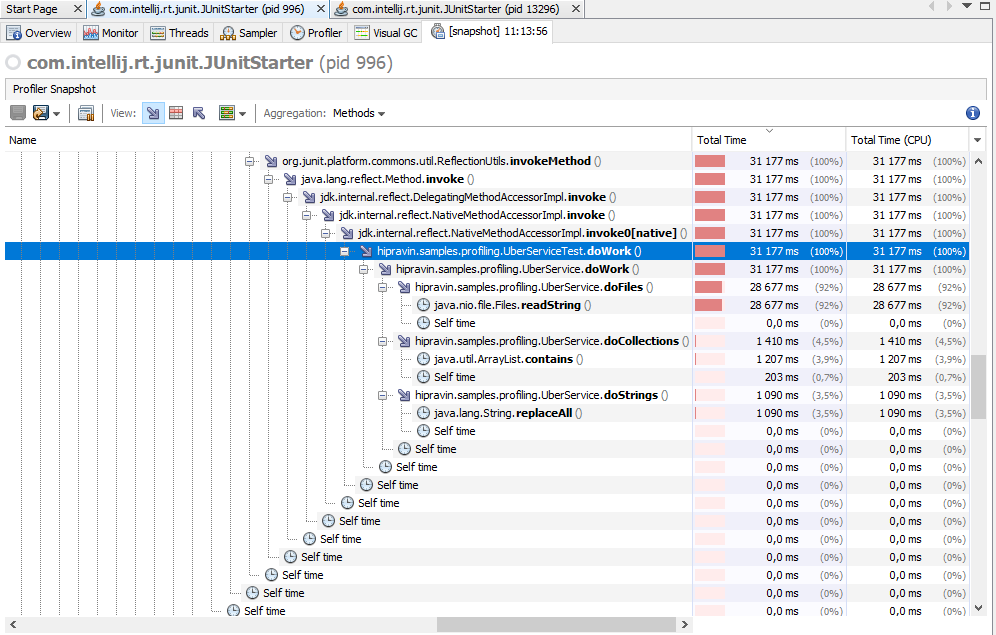
-
Закомментирую три этих метода, повторяю профилирование. Теперь в топ вышел метод, вызывающий библиотечное вычисление арксинуса.
Также очень медленно работает toBinaryString в сравнении с задачей, которую он решает. Синус в десять раз быстрее арксинуса, логарифм ещё в три раза быстрее.
Хотя от этой информации уже мало пользы, так как трудно представить алгоритм, где можно было бы синус заменить логарифмом.
public static void doMathAsin(int iterations) { double v = r.nextDouble(); double sasin = 0; for (int i = 0; i < iterations; i++) { sasin += Math.asin(v); } } public static void doBinaryString(int iterations) { long v = r.nextLong(); for (int i = 0; i < iterations; i++) { String s = Long.toBinaryString(v); s = s.substring(0, s.length() - 1); s += "0"; } } public static void doMathLog(int iterations) { double v = r.nextDouble(); for (int i = 0; i < iterations; i++) { v += Math.log(v); } } public static void doMathSin(int iterations) { double v = r.nextDouble(); for (int i = 0; i < iterations; i++) { v += Math.sin(v); } }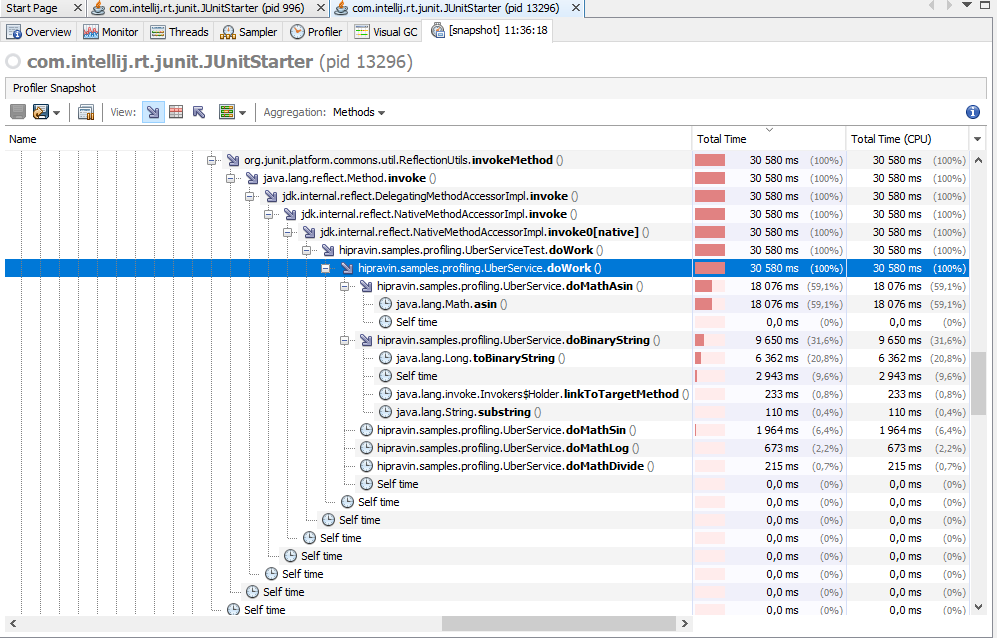
-
Эти четыре метода тоже комментирую, остаются только базовая математика и битовые операции. Заодно приходится поднять число итераций, и иначе тест сразу завершается.
Конкретным цифрам доверять опасно, потому что VisualVM не даёт точного бенчмарка, но когда производительность отдельных операций отличается значительно, то этого вполне достаточно.
Я ожидал, что деление и деление по модулю будет заметно медленнее сложения и умножения, но тест этого не показал. Возможно тест не точный, либо процессоры стали умнее.
Битовые операции очень быстрые, как и предполагалось.
public static void doBinary(int iterations) { long v = r.nextLong(); for (int i = 0; i < iterations; i++) { v = v >> 1 << 1; v = v ^ v ^ v; v = v & 0xFFFFFFFFL; } } public static void doMathPlusMul(int iterations) { long v = r.nextLong(); for (int i = 0; i < iterations; i++) { v = v + 1 - 2 * v; } } public static void doMathDivide(int iterations) { long v = r.nextLong(); for (int i = 0; i < iterations; i++) { v *= 2; v = v / 2 + v % 10000; } }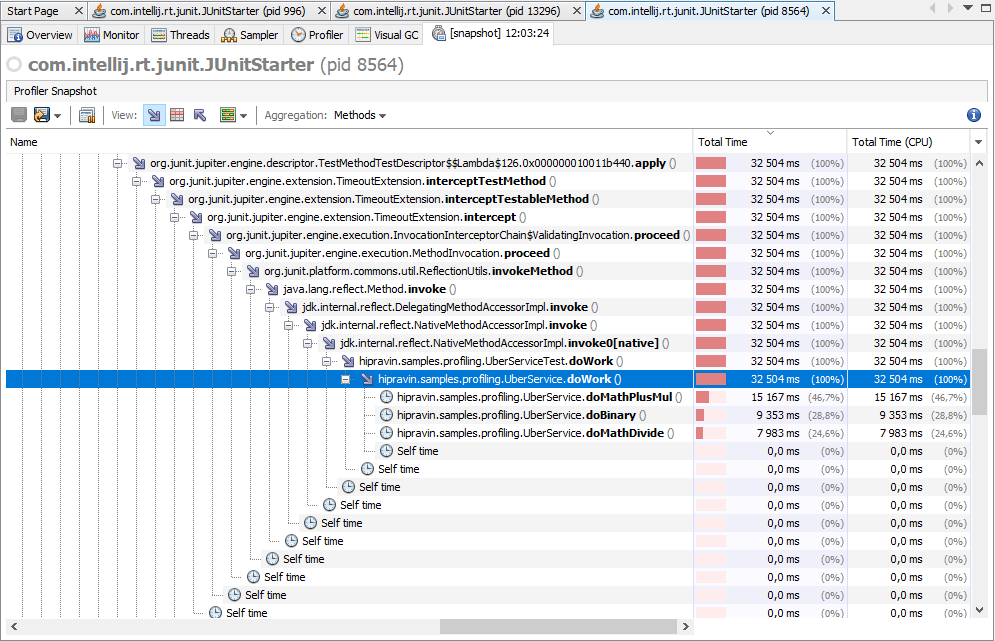
Этим примером я хотел показать важность нескольких моментов. Первый имеет место при написании кода. В Java считается плохим тоном и ошибкой излишне оптимизировать код лишаясь его краткости, лаконичности и читаемости. Но если, например, нам нужен косинус, а у нас уже есть синус (типичная ситуация в алгоритмах с векторами), то следует избегать очевидного косинуса от арксинуса, а вместо этого применить формулу (корень от 1 - cos^2). Такую оптимизацию сложно назвать излишней. Также нельзя битовые операции заменять на строковые, кроме тестов или мест, где это однозначно ничтожно влияет на производительность.
Второй момент - это исследование проблем с производительностью. Без визуального сравнения и профилирования в сложной системе было бы крайне трудоёмко отыскивать вручную самый медленный метод или запрос к базе данных.
Третий момент - решение проблем с производительностью. Если мы видим как один метод съедает 70-90% времени, то это прекрасно. Оптимизировав его, мы значительно ускорим приложение в целом. Однако после нескольких таких оптимизаций мы можем прийти к ситуации, когда несколько сложных методов требуют примерно равное количество ресурсов, при этом каждый уже более-менее оптимизирован и существенных недочетов по производительности в них нет. В таком случае задачу оптимизации уже не решить без серьезной переработки приложения. В редких случаях может помочь распараллеливание работы, но чаще придётся смириться с тем, что мы достигли ограничения в соответствии с текущим дизайном (выражение "by design").
Далее приведу запомнившиеся мне случаи проблем с производительностью в реальных приложениях и их решения. Очень часто причина заключается в неоптимальной работе с базой данных или проблемах в самой базе данных. В этих случаях профилирование помогает определить, какой именно запрос томозит.
- Долгий ответ от БД (например, SELECT FROM TABLE1 WHERE FIELD1 = ?)
- Причина - отсутствие индекса на поле FIELD1, в результате чего возникает так называемый full scan, когда нужен просмотр всей таблицы, чтобы найти записи. Решение - добавить индекс.
- Долгий ответ от БД при вычитывании большого количества записей
- Причина - Hibernate вычитывает записи по одной или маленькими порциями. Решение - увеличить hibernate.jdbc.fetch_size до 1000, значение по умолчанию 10.
- Очень медленное каскадное удаление из БД
- Причина - неиндексированные внешние ключи. Решение - создать индексы и каждый релиз отслеживать появление новых неиндексированных ключей. http://www.dba-oracle.com/t_find_foreign_keys_with_no_index.htm
- Неоправданно большое количество запросов к БД
- Разные причины. Проблема N+1 запроса, итерация по объектам с Lazy коллекциями и другие. Решение - рефакторинг кода, иногда кэширование результатов запроса.
- Медленная работа подсказок автозаполнения в браузере (autocomplete)
- Причина - обращение к БД на каждый AJAX запрос, неоптимальная работа с коллекциями. Решение - кэширование результатов, использование TreeMap.
- Медленная работа какой-то библиотеки после миграции с Weblogic 10 на Weblogic 12
- Для поиска причины пришлось применить всю мощь профилирования и дебага. Оказалось, что какой-то встроенный логгер низкого уровня, который даже не писал ни в какой поток вывода, стал себя вести по другому на новой версии и тормозить. Пришлось сравнивать результаты профилирования до и после, а потом в дебаге декомпилированного кода изучать отличия. Решение - удалось выключить лог вызовом статического метода на старте приложения. Более детально - не помню.
Заключение
Профилирование в VisualVM - очень удобный и полезный приём при изучении и улучшении производительности приложений. Существуют и намного более продвинутые инструменты: YourKit Java profiler, JProfiler. Для бенчмарка более правильным является JMH. Но для поиска причин "тормозов" мне на практике хватало VisualVM.