Когда заканчивается оперативная память (OutOfMemoryError)
Тема данного поста - довольно часто встречающаяся проблема переполнения памяти в Java. Постараюсь рассказать, почему этой ошибке стоит уделить особое внимание, почему так сложно искать причину и какие утилиты в этом помогают.
Ошибка OutOfMemoryError в java неизбежна. Если в нагруженном приложении такая ошибка не возникает, значит она была раньше и её починили. Я немного утрирую, но я не помню проекта, на котором бы такая ошибка рано или поздно не проявлялась. На собеседованиях вопрос про OutOfMemory не очень часто задают; честно говоря, редко кто отвечает правильно и подробно.
Даже несмотря на то, что такая ошибка может приводить к реальным убыткам, так как чаще всего возникает под нагрузкой, на production instance (продакшне, по-народному) и приводит к параличу системы на часы и более, всё равно в 90% случаев вместо поиска причины ошибки люди увеличивают объём памяти JVM (хоть до -Xmx64g) и настраивают еженедельные, а потом и ежедневные рестарты сервера. Чтобы система не повисала, настраивают мониторинги и когда память приближается к пороговому значению, проводят небольшой анализ, который, как правило, ничего не даёт, а уже потом перезагружают сервер.
Но что делать если рестарт или увеличение памяти не помогают? Тогда вся команда бросит свои текущие задачи и будет искать причину, воспроизводить, изучать логи, дампы памяти и потоков. Тогда, конечно, причину найдут и починят. Конечно, не всегда всё так серьезно, но бывает и так.
Как вообще происходит управление памятью в Java? Тот, кто знаком с языками С или C++,
знает каково это явно выделять память под каждый массив или объект и потом так же явно освобождать её.
Пример работы с массивом в C++:
int * p;
p = new (nothrow) int[1000]; //выделяем память под массив
if (p == nullptr) //обрабатываем ситуацию, если память выделить не удалось
cout << "Error: memory could not be allocated";
delete[] p; //освобождаем память после использования int[] array = new int[1000];
В Java же мы не управляем ни выделением памяти, ни его освобождением, ни моментом, когда память заканчивается. Попытка перехватить и обработать исключение OutOfMemoryError бессмысленна - после её возникновения дальнейшее поведение программы не определено. Вроде как память освобождает специальный сборщик мусора, но им тоже никак нельзя управлять. Его можно вежливо попросить освободить ненужную занятую память с помощью команды System.gc(), но этот вызов ничего не гарантирует. Под "утечкой памяти" применительно к Java подразумевают то, что объект, под который она выделена, никогда больше не будет использоваться в соответствии с потоком выполнения и логикой программы, но память, занимаемая им не может быть освобождена сборщиком мусора.
Можно выделить две основных причины OutOfMemoryError: первая - программе действительно нужно больше памяти, вторая - в программе присутствует утечка. Первый случай решается либо переработкой кода с целью эффективнее расходовать память, либо простым увеличением объёма памяти выделенной под процесс. Во втором же случае что бы мы не делали, память рано или поздно закончится, если причина утечки не будет исправлена. Почему же помогают рестарты сервера? Дело в том, что утечка расходует память не мгновенно. Например, после каждого вызова сервиса теряется один мегабайт. Если за сутки сервис вызывается 1000 раз, а для процесса выделено 2Гб, то ежедневные рестарты спасут от OutOfMemory, пока дневная нагрузка не поднимется сильно выше средней.
Я не привожу строгого формального описания процесса управления памятью в Java и работы сборщика мусора. Я считаю, что на практике в первую очередь нужно разобраться с основным принципом. Выделением и освобождением памяти занимается JVM. Так или иначе если объект становится неиспользуемым (недостижимым по графу ссылок), сборщик мусора его освободит до того, как память полностью закончится. Если объект всё ещё достижим, то память, занимаемая этим объектом, не будет освобождена вне зависимости от настроек сборщика мусора и конкретной его реализации. Появление достижимых объектов, которые более никогда не будут использоваться в программе - это утечка памяти, которую следует исправлять. Достижимость - это существование пути в графе ссылок от корневых объектов (GC Roots) до целевого объекта. Вот основные из них:
- Классы, их статические поля
- Все запущенные потоки
- Стек вызовов
- Локальные переменные и параметры функций
Упрощённо достижимость можно объяснить так: если в программе есть способ обратиться к объекту, значит он достижим (из GC Roots). Мы можем обратиться к статическим полям загруженных классов, к локальным переменным и параметрам, к текущему потоку. Утечек памяти, связанных с тонкостями определения корневых объектов, я не встречал. Возможно, они имеют место в случае использования собственных загрузчиков классов (custom classloaders). В такие дебри лезть не будем.
Рассмотрим несколько примеров. В первом создаём бесконечный список, OutOfMemoryError вылетает мгновенно.
IntStream.generate(() -> 1).boxed().collect(Collectors.toList());
//Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
// at java.base/java.util.Arrays.copyOf(Arrays.java:3689)
// at java.base/java.util.ArrayList.grow(ArrayList.java:237)
Во втором бесконечно вызываем String.intern, сохраняющий строку во внутреннем пуле.
Потребление оперативной памяти не растёт со временем, ошибка переполнения не происходит.
for(;;) {
UUID.randomUUID().toString().intern();
}
Теперь рассмотрим неочевидный случай, анализ которого потребует специальных утилит.
Код тут., хотя в нём буквально 10 строчек:
@RestController
@RequestMapping("/api")
public class OomRestService {
private final Logger log = LoggerFactory.getLogger(OomRestService.class);
@GetMapping("/ping")
public String ping(HttpServletRequest request) {
log.trace("req from {}, session id {}", request.getRemoteHost(), request.getSession().getId());
return "pong";
}
} @Test
public void testPingInfiniteOom() {
for(;;) {
ResponseEntity<String> ping =
testRestTemplate.getForEntity("http://localhost:" + port + "/api/ping", String.class);
}
}
Тест запускается с дополнительным аргументом виртуальной машины "-Xmx50m",
то есть всего 50 мегабайт, но для старта приложению достаточно и 20 мегабайт, а OutOfMemory мы получим и при гигабайте, только ждать дольше.
Ошибка случается через пару минут и около 80 000 вызовов сервиса.
Exception: java.lang.OutOfMemoryError thrown from the UncaughtExceptionHandler in thread "http-nio-auto-1-ClientPoller"
Exception in thread "RMI TCP Connection(idle)" java.lang.OutOfMemoryError: Java heap space
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
Первое, что нужно получить - дамп памяти процесса JVM перед падением. Для этого тест следует запустить с дополнительным параметром:
-XX:+HeapDumpOnOutOfMemoryError
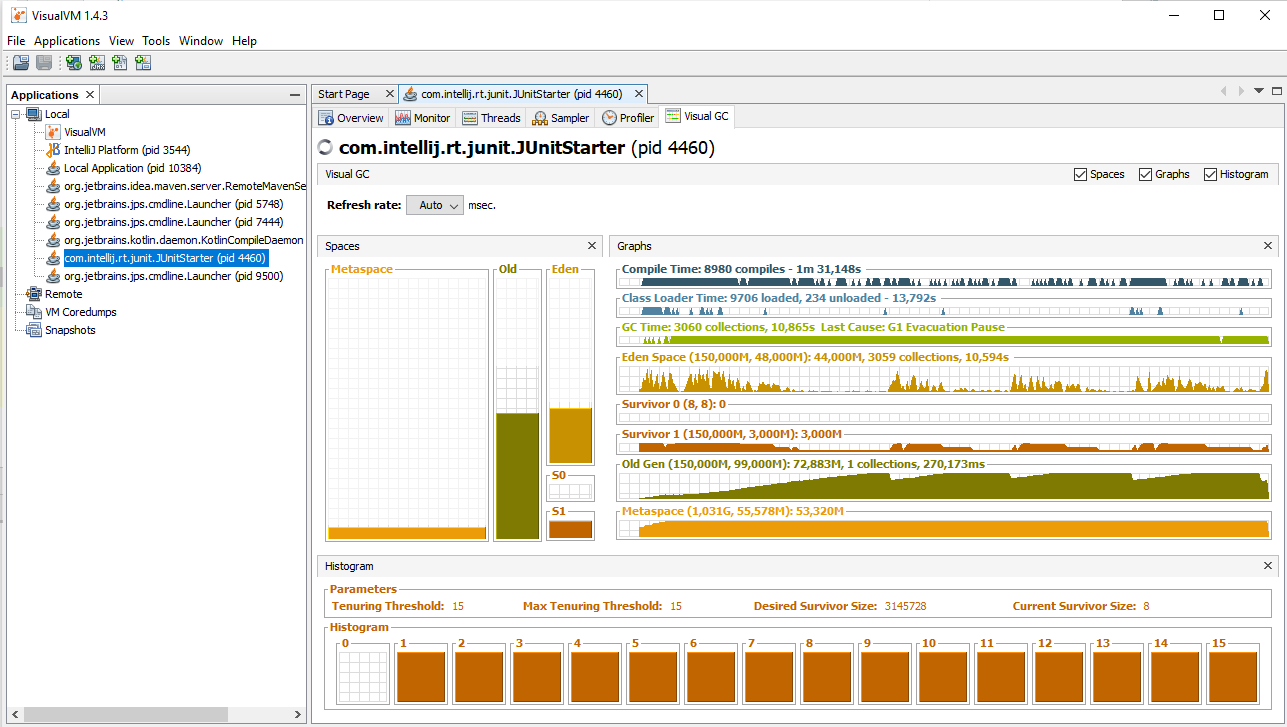
Первая - Visual VM. До Java 9 эта утилита входила в состав Oracle JDK. В более поздних версиях устанавливается отдельно. Позволяет подключиться к процессу с помощью технологии JMX и осуществлять разнообразную диагностику и даже управление. Например, можно изучать состояние потоков, загрузку процессора и памяти. Для данного примера я установил плагин VisualGC (Tools->Plugins). С его помощью мы в динамике сможем понаблюдать за заполнением памяти и состоянием программы в момент возникновения OutOfMemory. Если процесс запущен локально, то подключение не вызывает проблем, никаких портов специально открывать не нужно.
Вторая утилита - Eclipse Memory Analyzer Tool. С её помощью мы будем анализировать дамп памяти, чтобы определить вероятные причины проблемы.
Итак, запускаем тест с параметрами "-Xmx50m -XX:+HeapDumpOnOutOfMemoryError", после чего сразу запускаем VisualVM. В левой панели видим список всех Java процессов, запущенных на локальной машине. Среди них будет IDE, VisualVM и прочие. Нам нужен com.intellij.rt.JUnitStarter, он добавится в список через пять-десять секунд, выбираем его и подключаемся двойным щелчком левой кнопки мыши. Теперь открываем вкладку Monitor или VisualGC и ждём, пока программа не упадёт. Очень познавательно наблюдать за работой сборщика мусора вот так наглядно. Видно, как меняются графики, когда памяти остаётся мало. Таким образом можно исследовать приложение: совершать пользовательские операции и сразу же визуально оценивать их влияние на потребление ресурсов. В нашем случае никаких операций совершать не нужно, просто ждём две-три минуты. Процесс завершается с ошибкой, а в корне проекта создаётся файл .hprof (в моем случае, java_pid11712.hprof, 85мб), размер которого сопоставим с объёмом выделенной памяти. Вот что получилось у меня:
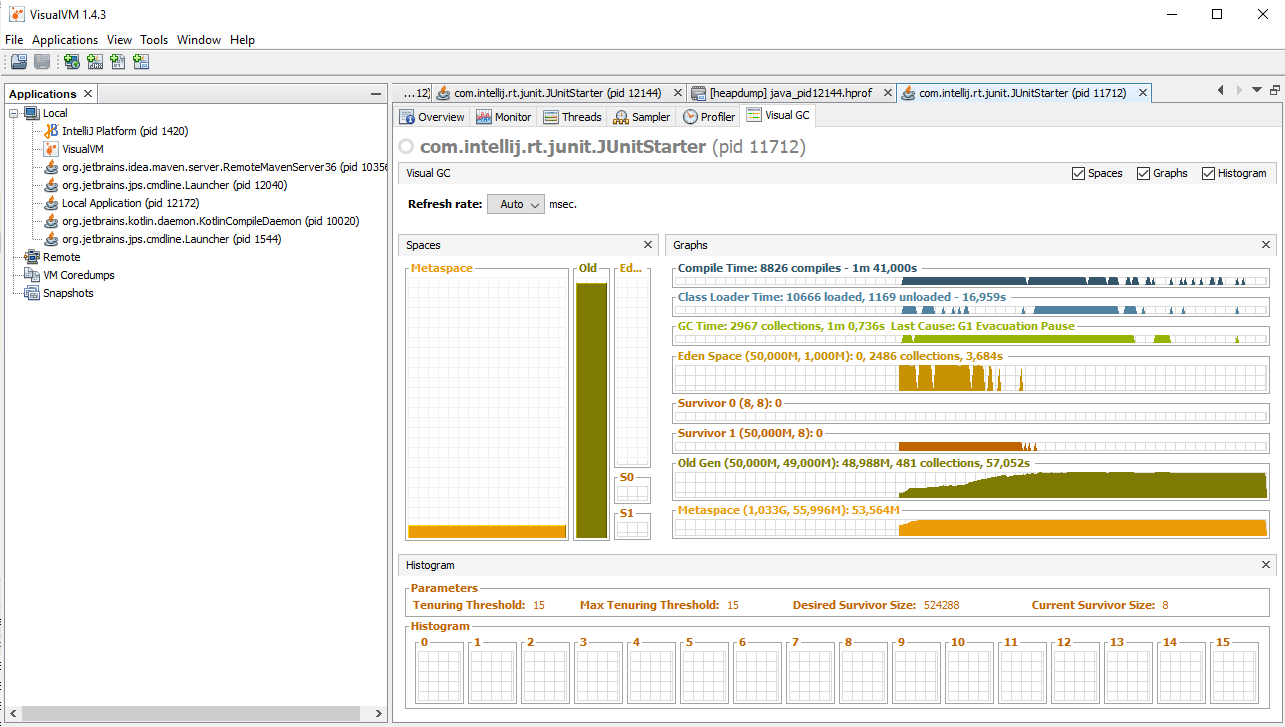
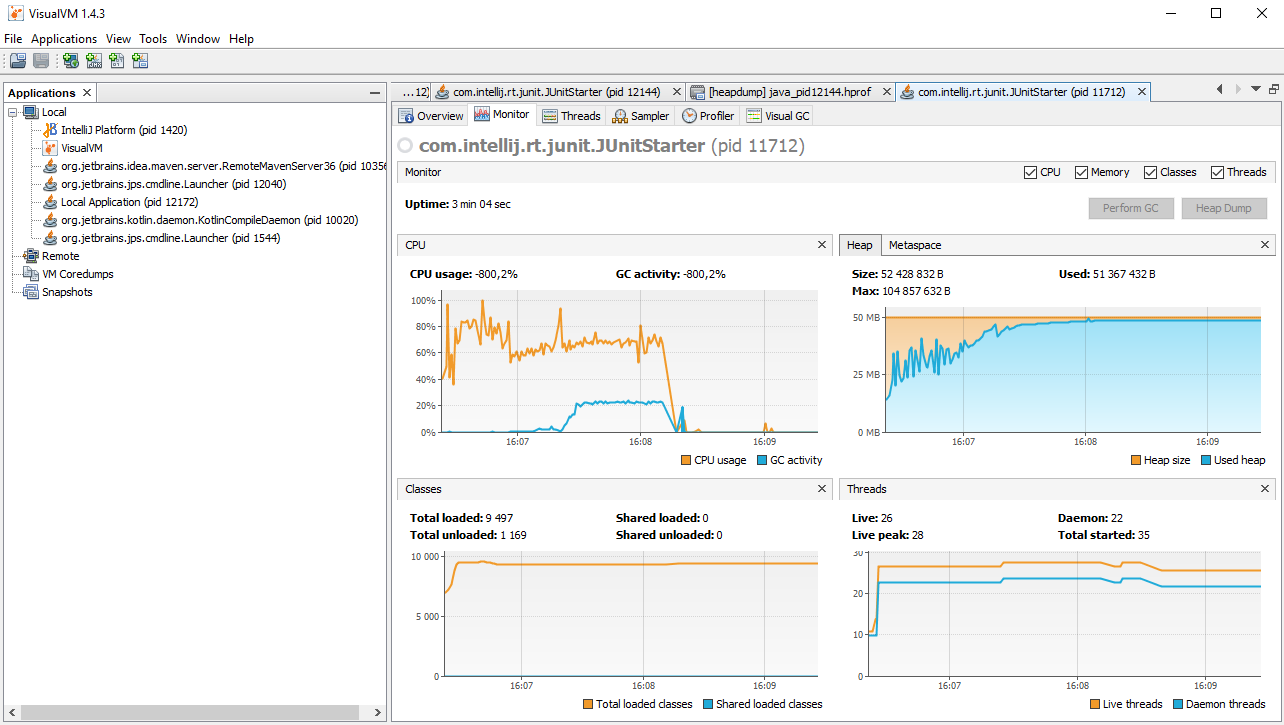
Следующий шаг - запустить Eclipse MAT, открыть дамп памяти и произвести поиск утечек (File->Open Heap Dump->Leak Suspect). Логика определения утечек следующая - если в нормальном состоянии работы приложения занято не больше 50-60 процентов от всей выделенной памяти, то переполнение происходит от того, что какой-то объект или однотипные объекты, накапливающиеся в результате утечки памяти, занимают всё оставшееся место. По дампу памяти несложно определить что, скажем, вся память забита объектами типа String, но это не очень полезно. Eclipse MAT же строит дерево на основе ссылок и показывает подозрительные узлы, суммируя память по всем поддеревьям. Результат анализа дампа нашего теста:
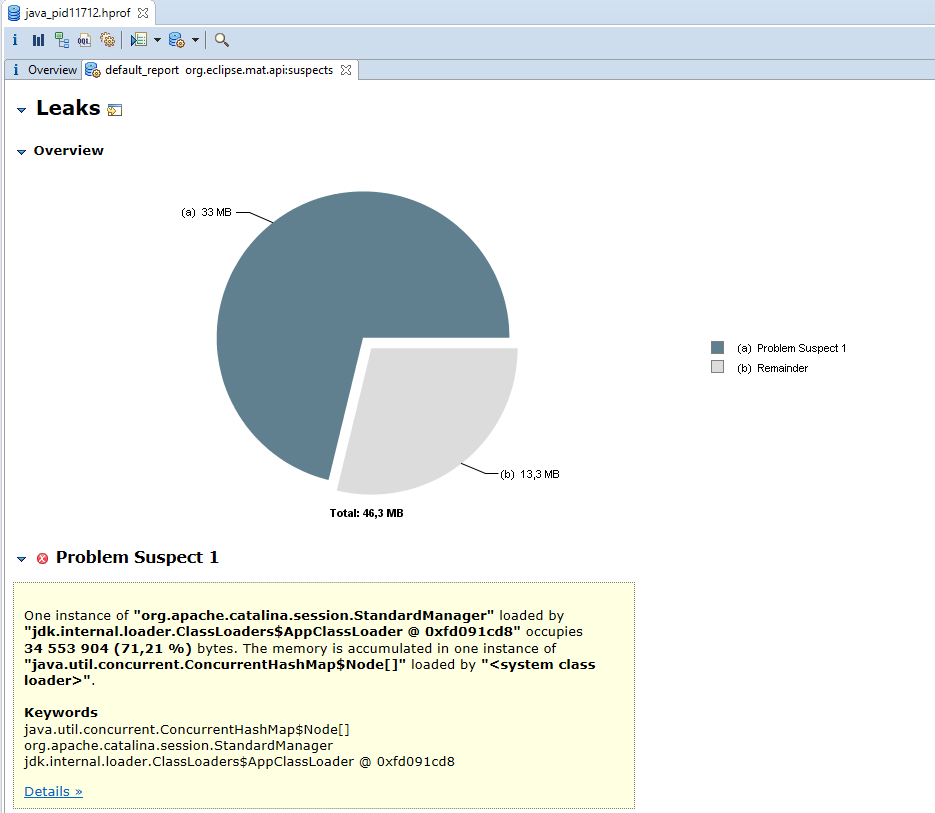
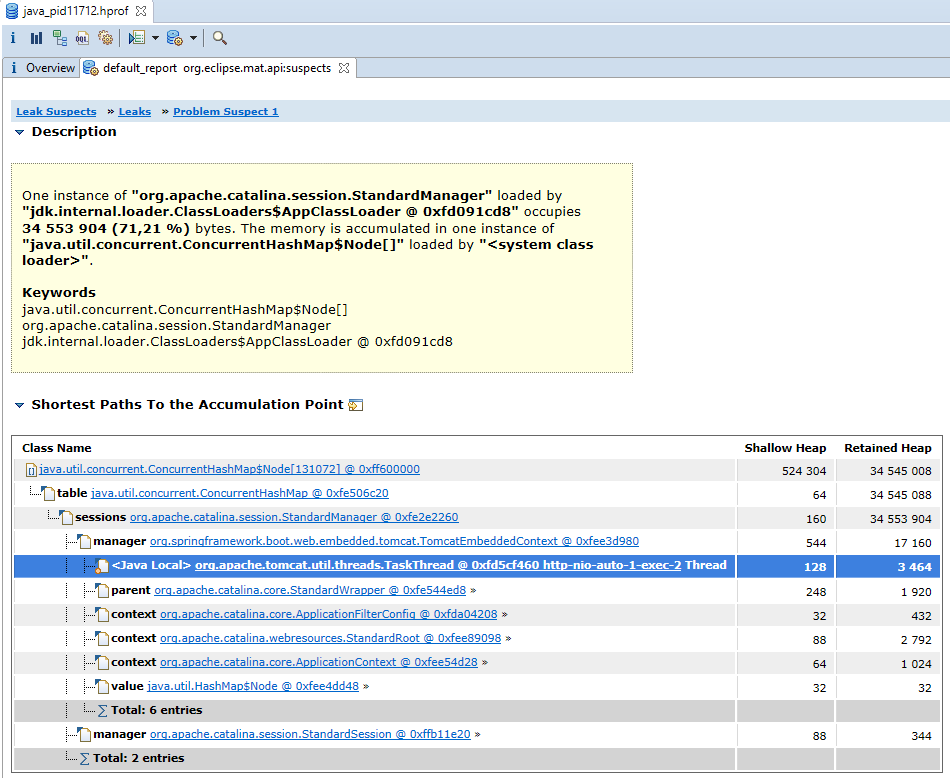
Видно, что 71% занятой памяти как-то связан с классом org.apache.catalina.session.StandardManager. Это-ещё не ответ, а лишь подсказка и предположение, которое следует проверить. Но оно очень ценно, без него мы были практически в тупике.
Следующие шаги поиска проблемы будут напрямую зависеть от того, чем занята память, здесь нет общего рецепта. Может быть, это будет какой-то кэш, который не очищается, может нагрузка слишком велика и столько одновременных запросов система не способна обработать.
Конечно, в данном случае я точно знал причину заранее. Она следует из принципов работы технологии сервлетов. На каждый новый запрос, поступающий к приложению, создаётся объект HttpSession, а пользователю в ответе добавляется заголовок, устанавливающий куку JSESSIONID. За счёт этого работает аутентификация и всевозможное кэширование. Это особенно характерно для корпоративных приложений, в которых обычно небольшое количество пользователей, но приличный объём данных и очень сложная бизнес логика. Главная страница открывается долго, потому что загружаются и обрабатываются сложные структуры данных, права, настройки текущего пользователя. Всё это сохраняется в сессии (наподобие session.setAttribute("settings", settings)).
Потребовалось 80 000 пустых сессий, чтобы заполнить 50мб памяти. При использовании фреймворка Vaadin одна сессия по слухам требует уже 0.1мб, ну а в реальном приложении можно и всю память забить данными, сохранёнными в атрибутах одной сессии. Важно здесь то, что сессия создаётся на каждый запрос и остаётся активной до истечения таймаута, который по умолчанию составляет 30 минут.
Если установить малое значение, то сессии начнут становиться неактивными быстрее, чем переполнится память.
Проверим это предположение и установим таймаут в одну минуту:
server:
servlet:
session:
timeout: 1
Сессия не создавалась бы вовсе, если бы не вот эта строчка кода, которая имитирует неаккуратное логирование, приводящее к побочным эффектам:
log.trace("req from {}, session id {}", request.getRemoteHost(), request.getSession().getId());
- Воспроизведение OutOfMemoryError
- Получение дампа памяти
- Диагностика приложения в динамике
- Анализ дампа памяти, гипотеза
- Проверка гипотезы
- Hotfix: Быстрое решение, чтобы починить приложение прямо сейчас
- Long term solution: Правильное решение, исправление кода или даже изменение дизайна.
У нас быстрое решение - уменьшить таймаут сессии и, по возможности дать больше памяти процессу. Правильное решение - перейти на stateless сервис, удалить ошибочное создание сессии без необходимости либо уменьшить размер данных, хранящихся в сессии, перейдя на специализированные библиотеки кэширования.
Если Вы сами повторяли шаги анализа, то могли заметить, насколько приложение замедляется перед тем, как случается ошибка OutOfMemoryError.
Плата за удобство управления памятью - время, которое требуется сборщику мусора на каждый цикл его работы.
Реализация сборщика мусора G1, которая используется по умолчанию, периодически полностью останавливает выполнение команд.
Это называется Stop-the-world. Другие стандартные реализации поступают так же: Serial, Parallel, CMS.
В обычном состоянии эти паузы малы и практически не влияют на производительность, хотя и не позволяют использовать Java для "real time" приложений.
Но когда существует утечка и свободной памяти остаётся всё меньше, работа сборщика мусора превращается в сизифов труд.
Такое состояние ещё хуже, чем если бы ошибка выпадала сразу.
Иногда JVM удаётся определить подобное состояние и выбрасывается исключение:
java.lang.OutOfMemoryError: GC overhead limit exceeded
В заключении приведу несколько примеров реальных и выдуманных ситуаций, приводящих к переполнению памяти и варианты решения.
Кэширование
Если применяется библиотека кэширования, то следует ограничивать не только максимальное время жизни объектов и их количество,
но и максимальный объём памяти. Тогда переполнения точно не случится, в худшем случае мы получим слишком быстрое удаление объектов из кэша.
Пример конфигурации для Hazelcast:
<max-size policy="USED_HEAP_SIZE">4096</max-size> <gfe:partitioned-region-template id="PartitionRegionTemplate" template="ExtendedRegionTemplate"
copies="1" load-factor="0.70" local-max-memory="1024"
total-max-memory="16384" value-constraint="java.lang.Object">
Неожиданно большие коллекции в базе данных
При использовании в JPA отношений OneToMany или ManyToMany, когда загрузка одного объекта из базы влечет за собой загрузку списка связанных объектов, существует два варианта загрузки: ленивый и жадный (Lazy, Eager). При разумном подходе все коллекции либо, по крайней мере, большую часть помечают как Lazy. Это означает, что они не будут инициализироваться без необходимости. Но для удобства часть коллекций можно оставить как Eager. Подобные коллекции могут привести к переполнению памяти, если их размер со временем разрастется в связи со спецификой нагрузки на продакшне. Другой случай - коллекция действительно нужна в конкретном сценарии использования. Скажем, мы показываем администратору неудачные попытки ввода пароля за сутки на одной странице. Обычно их 10 - 100. Код может работать отлично, пока это предположение не нарушено, но в один прекрасный день в результате какой-нибудь DDOS атаки или просто ошибки в коде, коллекция вырастает до 500 000 элементов, и приложение закономерно падает с OutOfMemoryError. На практике лучше избегать предположений по размеру коллекций. Возможно, для этого придётся поменять бизнес требования, реализовывать постраничное отображение информации или ограничения (constraints) на уровне базы данных.
Неожиданно большие файлы
Если входные данные от сторонних систем поступают в виде файлов, нужно избегать полной загрузки файла в память. Скорее даже не самого файла, а объектной модели, соответствующей его содержимому. Для большинства форматов данных (например, JSON, XML, CSV) существуют способы потоковой обработки информации без отказа от удобной объектной модели.
Утечки в сторонних библиотеках
Они - возможны, но намного реже утечек в коде приложения. Такие проблемы исследовать очень тяжело. Если на основе анализа в Eclipse MAT появляется гипотеза о некорректном поведении библиотеки, то чтобы её проверить может потребоваться разработка синтетического приложения, которое отражает только один сценарий работы приложения, связанный с этой библиотекой, а всё остальное из него исключено. Впрочем, этот подход справедлив для исследования любых подозрений на ошибки в сторонних библиотеках, не только об утечках памяти.
Заключение
Причины ошибки переполнения памяти слишком разнообразны, чтобы можно было предложить универсальное решение. Однако разумный подход и знание типовых ошибок во многом спасает.