Сегодня речь пойдёт о Maven. Это в первую очередь утилита для сборки Java проектов, но по факту является системой управления проекта в целом,
определяет его структуру и, во многом, жизненный цикл. (Apache Maven is a software project management and comprehension tool. Project object model (POM))
Работая с базовыми сценариями в хорошо настроенном окружении, программисту не требуется глубоко вникать в тонкости этой технологии.
Но стоит проекту Maven перестать собираться, как легко можно попасть в тупик, для выхода из которого требуется опыт и понимание определённых нюансов.
Почему не находится плагин? Зачем он лезет в интернет? Почему падает деплой артефакта? Откуда взялась библиотека log4j первой версии?
Почему сборка работает локально, а на Jenkins падает? У меня в IDE всё компилируется, а Maven что-то тупит. Вспоминать и фантазировать можно долго.
Многие скажут, что я утрирую, но Вы
можете поверить, что люди переходили с Eclipse на IDEA после трёх и более лет разработки потому, что сложный maven проект отказывался нормально импортироваться в Eclipse,
но коллеги пользовались IDEA и никто не мог помочь настроить его в Eclipse?
Но даже учитывая всё это, использование Maven - это необходимость и меньшее из зол.
Maven заставляет всех разработчиков делать одинаково и более менее правильно. Это касается структуры проектов, расположения и имён определённых файлов,
управлениями модулями, зависимостями и в определённой степени процессом релизов.
Как развивались некоторые проекты, пока их не мигрировали на maven?
Все известные мне проекты собирались с помощью утилиты Ant.
Не знаю, смог ли кто-то настроить компиляцию и сборку с использованием непосредственно утилиты javac,
поставляемой вместе JDK а также shell или bat скриптов, но это было бы уж слишком безумно.
Большинство вполне успешно обходилось утилитой Ant.
Давайте пофантазируем, как это было. Куда положить исходный код? Ну, допустим ./src/Main.java или ./src/com/example/Main.java, если с пакетами.
Куда проперти файлы? Давайте туда же ./src/log4j.xml. Но не все, что-то положим в ./conf. Куда будем складывать скомпилированные файлы? Мне нравится ./dist.
А тесты? В ./test/src, а данные для теста в ./test/*, то есть рядом с исходниками. Честно говоря, я подсматриваю в реальном проекте.
Если вы уже имеете опыт разработки, то уже чувствуете отсутствие стандарта - вроде всё логично, но в то же время наобум.
И на каждом новом проекте будет похоже, но по-другому.
Кстати, а библиотеки мы куда положим? В ./lib, конечно же. Стоп! Что значит положим библиотеки, разве они не должны храниться централизованно и выкачиваться автоматически при необходимости?
Нет, библиотеки скачивают, потом обычно из переименовывают из log4j-1.2.12.jar в log4j.jar,
чтобы версию уже никак нельзя было определить, разве что её заботливо указали в MANIFEST файле внутри библиотеки.
Естественно, библиотеки сохраняются и в системе контроля версий, и таким образом любой проект весит уже никак не меньше 20-50 мегабайт.
С библиотеками вообще очень неудобно - начинаешь новый проект и каждую библиотеку скачивать из интернета и сохранять в проекте неудобно, ещё и может понадобиться в IDE явно её добавлять.
Но был найден удобный и эффективный подход, решающий все проблемы - мы будем копировать lib из проекта в проект. Со временем там окажутся все нужные нам библиотеки:
логгеры, драйверы всех баз данных, spring, apache commons, junit, сервлеты,...
Ну вот у нас есть исходные файлы, мы настроили IDE, указав пути к ним, добавили библиотеки. Пришло время показать наше приложение кому-то, а на местном наречии - "выложить".
Выложить в тестовую среду или продакшен. В случае web приложения это означает, что нужно создать ZIP архив фиксированной структуры, состоящий из скомпиливанных классов, файлов настроек, библиотек и
ещё пары специальных файлов. Этот архив называется WAR-архивом (или варником). Для всего этого и создаётся Ant сборка. Чаще всего это файл с названием build.xml, в довесок к которому идёт build.properties.
Пример содержимого такого фэйла:
Я не буду вдаваться в детали, скажу лишь что это практически минимальная конфигурация.
Для Maven аналогичная по функциональности конфигурация заняла бы пять или десять строк кода.
По сути Ant build представляет собой пошаговую инструкцию, как собирать проект: компилируем, копируем, копируем, архивируем, точно указывая где что лежит и как называется.
Эти билды очень быстро разрастаются, в них появляются схожие, но немного отличающиеся target'ы: собрать для локального запуска, собрать для INT и так далее.
Но управляться вручную с библиотеками совсем неудобно и появилаяь надстройка Ivy.
<ivy-moduleversion="2.0"><infoorganisation="org.apache"module="hello-ivy"/><dependencies><dependencyorg="commons-lang"name="commons-lang"rev="2.0"/><dependencyorg="commons-cli"name="commons-cli"rev="1.0"/></dependencies></ivy-module><projectxmlns:ivy="antlib:org.apache.ivy.ant"name="hello-ivy"default="run"><targetname="resolve"description="--> retrieve dependencies with ivy"><ivy:retrieve/></target></project>
Зависимости выкачиваются из maven репозитория.
В целом Ant+Ivy представляет из себя аналог Maven по функционалу, но конфигурации получались корявые, проблем с ними было достаточно.
В какой-то момент старые проекты начали переносить c Ant на Maven. Новые проекты тоже сразу использовали Maven.
Но если Ant позволял практически составить пошаговую программу для сборки, использовать произвольные команды в произвольном порядке,
то в Maven ситуация иная. Ровно так, как задумано, сделать легко. Чуть отступить - тяжело. Сделать совершенно по-другому - почти невозможно.
В Ant сборке легко скопировать файл из одной директории в другую, можно и переименовать заодно. В Maven правильный ответ на эту задачу: "А зачем?".
Очень много задач, которые Ant решал относительно легко, в Maven упираются в этот вопрос. Зачем копировать файл из одного места в другое? Копировать нужно файлы конфигурации,
они лежат в src/main/resources, и копируются автоматически в target/classes. Скомпилированные java классы тоже в этой папке, библиотеки тоже сами копируются если нужно куда следует.
Вы копировали артефакт сборки на сервер (например, project.war -> tomcat/webapps) прямо из сборки? Будьте добры переделать, Maven не для этого.
Вы собирали из одних исходников одновременно war и jar? Возможно сделать что-то похожее, но лучше сделайте два разных модуля.
Последний вопрос - я сразу из Ant очищал базу данных вот так, как мне перенести это в Maven:
<targetname="droptables"description="Drop DB tables"><echomessage="DROP TABLES USING: ${db.driver} ${db.url}"/><sqldriver="${db.driver}"url="${db.url}"userid="${db.user}"password="${db.pw}"onerror="continue"><classpathrefid="master-classpath"/>
USE internet_shop;
DROP TABLE ordtoprd_odp;
DROP TABLE order_ord;
DROP TABLE product_prd;
DROP TABLE client_cln;
DROP TABLE product_ctg;
</sql></target>
Никак. Удали. Отстань.
В результате после миграции на Maven мы получаем для проекта:
Приведение всех проектов к общей структуре
Удаление несвойственных шагов из процесса сборки
Работу с библиотеками только через зависимости и центральный репозиторий
Работу с артефактами сборки проекта так же, как и с библиотеками, понятный механизм релизов-снепшотов
Модули - части проекта с разным набором библиотек и исходным кодом,
между которыми можно устанавливать зависимости, которые Maven самостоятельно будет "разруливать"
В то же время для разработчика:
Необходимость изучения Maven, его идеологии и основных плагинов
Проект импортируется в IDE простым открытием файла pom.xml, все настройки производятся автоматически.
Не нужно и неправильно сохранять в GIT/SVN проект IDEA или Eclipse. Не нужно указывать IDE где лежат библиотеки, где конфигурация и исходники,
какой уровень языка использовать для компиляции.
Новые проекты создаются с минимальной конфигурацией, небольшие изменения требуются только по необходимости.
Встроенная удобная работа с генерируемыми исходники, например, для SOAP веб сервисов. Существует отдельная фаза generate-sources,
при этом эти файлы никогда случайно не попадут в GIT, но при этом и в IDE они появляются сами когда нужно, и во время сборки тоже.
Ant система сборки, Maven система сборки, но что это значит, какую задачу они решают?
В мире Java код хранится в репозитории, но на нормальных проектах на продакшен код никогда не развертывается и не компилируется из репозитория напрямую.
Собранный проект или вернее, артефакт сборки, должен потерять все связи с репозиторием, генерацией исходников, компиляцией, подстановкой плейсхолдеров в файлах конфигурации,
всё это должно произойти на этапе сборки и быть зафиксировано однозначно.
Собранный артефакт может и должен указывать на номер коммита в системе контроля версий, на основе которого он был собран, но это только для поддержания порядка в системе.
Для этого можно использовать MANIFEST файл, включаемый в WAR или JAR.
Данное разделение между исходным кодом и собранным артефактом создано искусственно, но оно необходимо.
Это один из способов контролировать и стабилизировать работу продакшена. Хотя maven не справляется в одиночку, нужны ещё системы continuous integration (Jenkins, TeamCity).
Не строгое следование этому разделению всегда приводит к багам, связанным не с ошибками в коде, а с тем,
что не та версия кода или неправильно собранная версия кода попадают в тестовую или продакшен среду.
Трудно передать словами важность этого, но по моему опыту, это намного эффективнее приводит к существенным сбоям, влекущим в том числе к финансовым затратам, чем ошибки в коде.
Итак, maven осуществляет генерацию кода при необходимости, компиляцию, запускает тесты, собирает результат в архив WAR/EAR или JAR, в один или несколько.
Далее всё зависит от настроек процесса CI/CD (continuous integration / continuous delivery).
Иногда эти файлы сразу копируются, например, в Tomcat и далее перемещаются с одной среды на другую и, в конечном итоге, на продаакшен. В этом случае базовой командой будет "mvn package"
Более современный подход - поместить артефакты сборки в центральный репозиторий (Artifactory/Nexus).
Этот шаг осуществляет maven, а команда выглядит так: "mvn deploy".
Небольшое замечание про docker. Не могу авторитетно утверждать, как правильнее всего связывать docker и maven и в каком порядке.
Думаю, что разумно рассматривать готовый docker контейнер как артефакт сборки проекта, только на другом уровне абстракции.
А вот с системой контроля версий maven не должен контактировать никак.
Существует плагин maven-release-plugin, который кроме прочего умеет коммитить файлы, но он не прижился.
Я встречал пару попыток его применить, но после того, как история изменений забивалась коммитами от maven, от него отказывались.
Я твёрдо убежден, что maven не должен ни "чекаутить", ни "коммитить" файлы. Загружает из системы контроля версий пусть Jenkins, а сохраняет - только человек.
От слов к делу
Теперь попробую рассказать более конструктивно, что же из себя представляет Maven. Для начала нам потребуется сам дистрибутив, установка которого заключается в распаковывании и добавлении
команды mvn в PATH. Дистрибутив, размещённый на официальном сайте отлично подходит.
В IDEA тоже есть встроенный maven и он тоже вполне рабочий. Удобнее всего пользоваться сохранёнными конфигурациями запуска в IDEA, но использовать при этом отдельно установленный Maven.
Хотя возможно всю работу осуществлять через консоль. Так или иначе, команда mvn - главный и единственный интерфейс работы с Maven,
будем ли мы его вызывать сами или через сохранённые конфигурации в IDEA.
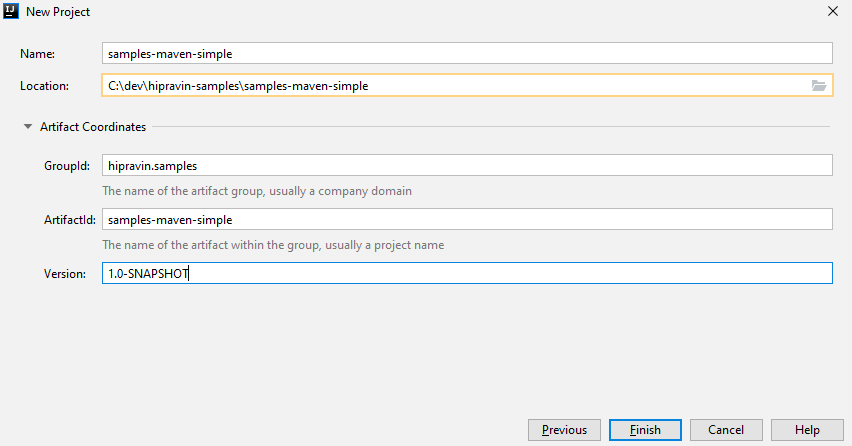
Давайте создадим минимальный проект и будем его понемногу дополнять. В IDEA это можно сделать через меню File -> New -> Project... -> Maven -> Next.
Нужно указать только group id, artifact id и version. На archetype не обращаем внимания. Скриншот чуть ниже.
Содержимое файла pom.xml в результате:
Небольшое отступление: следующим шагом я сразу добавляю файл .gitignore, копируя его из другого проекта.
Когда проекты создаются через Spring Initializer, этот файл присутствует по умолчанию.
Без него легко первым же коммитом создать бардак в репозитории.
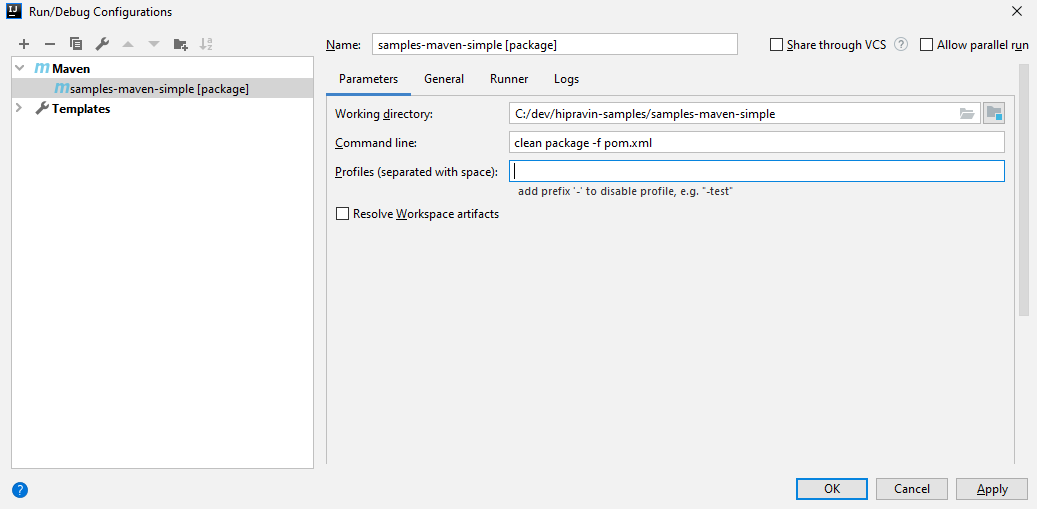
Все mvn команды я буду запускать через IDEA, как показано на скриншоте.
Это полностью эквивалентно консольной команде:
mvn clean package
Команда завершается успешно, в папке ./target появился файл samples-maven-simple-1.0-SNAPSHOT.jar.
В нём только сам pom.xml и MANIFEST.MF следующего содержания:
IDEA подчёркивает repeat красным, а сборка падает с ошибкой
[ERROR] COMPILATION ERROR :
[INFO] -------------------------------------------------------------
[ERROR] Source option 5 is no longer supported. Use 6 or later.
[ERROR] Target option 1.5 is no longer supported. Use 1.6 or later.
[INFO] 2 errors
[INFO] -------------------------------------------------------------
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
Действительно, метод repeat в классе String появился только в Java 11, но мы вообще не указали уровень языка.
Можно указать в IDEA, но после первого же реимпорта проекта всё опять сломается.
Для решения проблемы нужно уточнить конфигурацию плагина maven-compiler-plugin.
Именно уточнить, потому что плагин уже включен и применяется на стадии compile, входящей в package,
но настроен по умолчанию.
Так и поступим. Теперь проект компилируется и в IDE, и Maven'ом через консоль.
Плагины - это рабочие лошадки Maven'а. На данный момент по команде package запускается уже четыре плагина:
maven-resources-plugin обрабатывает и копирует файлы конфигурации; maven-compiler-plugin компилирует код включая тесты, преобразуя .java в .class;
maven-surefire-plugin запускает тесты, которых пока нет; maven-jar-plugin пакует результат сборки в JAR файл.
Плагины не общаются между собой и запускаются последовательно в определённом порядке, а результат их работы обычно представляет собой различные файлы в директории target.
Если какой-то из плагинов завершится с ошибкой, то вся сборка остановится.
Теперь подключим какую-нибудь библиотеку, например, jackson-databind и напишем простой тест, который будет падать.
Для тестов нам понадобится ещё подключить Junit, а класс теста поместить в папку ./src/test/java. Кроме этого имя класса должно иметь постфикс 'Test'.
Это правило, по которому surefire-plugin выбирает классы, в которых уже по аннотациям @Test выбирает методы для запуска.
Изменения в pom.xml:
Тут произошло то, чего я не ожидал - сборка прошла успешно, но при этом ни одного теста не запустилось.
Причиной оказалось использование Junit 5 при том, что версия surefire-plugin оказывается ниже необходимой.
Это решение я нашёл тут, и указание версии плагина помогло.
При использовании Spring Boot это явно не требовалось, потому что версия приходила из парента, но об этом позже.
Если исправлять тест нам сейчас не с руки, то можно запустить сборку с исключением всех тестов:
mvn clean package -DskipTests
Компиляция тестовых классов всё равно осуществляется, но не запуск.
Теперь сборка прошла, давайте снова посмотрим на содержимое собранного jar файла.
По сравнению с прошлым разом добавились только скомпилированные классы из папки src/main/java. А библиотеки?
Нет, их нет и не должно быть. Это WAR/EAR содержат все зависимости внутри архива, а также Spring Boot
за счет специального spring-boot-maven-plugin.
У нас есть главный класс, который мы хотели бы запустить, но обычно jar файлы - это всевозможные библиотеки и если бы каждая из них содержала внутри все зависимости,
то они бы повторялись многократно и общий размер рос бы рекурсивно в геометрической прогрессии (или экспоненциально?).
Как же тогда запустить нашу программу? Теоретически можно так:
Работает, но стоит нам в HelloWorld использовать что-то из классов Jackson, получаем ошибку
Exception in thread "main" java.lang.NoClassDefFoundError: com/fasterxml/jackson/databind/ObjectMapper
at hipravin.samples.HelloWorld.main(HelloWorld.java:7)
Caused by: java.lang.ClassNotFoundException: com.fasterxml.jackson.databind.ObjectMapper
at java.base/jdk.internal.loader.BuiltinClassLoader.loadClass(BuiltinClassLoader.java:583)
at java.base/jdk.internal.loader.ClassLoaders$AppClassLoader.loadClass(ClassLoaders.java:178)
at java.base/java.lang.ClassLoader.loadClass(ClassLoader.java:521)
... 1 more
Очень частая ошибка при любой ручной работе с библиотеками, когда программа запускается из консоли.
Вариантов решения несколько, строго правильного нет, надо выбирать по ситуации.
Вариант хитрый - подсмотреть как IDEA запускает программу:
Ох, лучше бы не видел. Посмотреть иначе список зависимостей можно командой "mvn dependency:tree", а скачиваются они в папку C:\Users\HiPravin\.m2\repository,
где уже разделены по директориям в соответствии с group id, artifact id и version. Формировать строку запуска можно безумными shell скриптами, склеивая пути ко всем библиотекам через точку с запятой.
Кстати, что тут делают библиотеки junit? Чтобы их не было, нужно указать scope = test вот так:
Теперь мы снова можем запустить программу, не перечисляя все библиотеки, а за счёт указания mainClass можем использовать команду "java -jar" и не указывать его явно в терминале.
Но давайте посмотрим, что из себя представляет jar-with-dependencies. Все библиотеки оказались распакованы, и .class файлы из них лежат в корне вместе с классами приложения.
Это нехорошо. Теперь как минимум будет очень сложно определить, что же за библиотеки использовались и каких версий, и в целом побочные эффекты очень вероятны.
Но без Spring Boot и его специального плагина избавиться от этого сложно. Можно настроить assembly plugin, чтобы библиотеки не распаковывались, но зависимости в виде .jar внутри
JAR файла будут лежать мертвым грузом и не будут добавлены в classpath.
Добавлю пару комментариев про assembly плагин. Это очень мощный инструмент, позволяющий производить сложные сборки приложения в нестандартном формате.
Если раньше сборка производилась сложными скриптами или сложным Ant билдом, то часто это удаётся повторить в Maven с помощью assembly.
Указать какие зависимости из каких модулей взять, какие ресурсы из каких папок, архивация-распаковка, переименование, включение и исключение - всё это возможно.
Конфигурация хранится отдельно в специальном формате, обычно файл называют assembly.xml.
По моему опыту файл получается красивым и выразительным, но на его создание уходит очень много времени.
А сделать быстро, но не столь красиво и не особо вдаваясь в детали, не получается - всё время будет собираться не так, как нужно.
Настораживает только одно, assembly по замыслу - простой плагин для базовых операций, а для продвинутых существует... ещё один плагин, который называется "shade" плагин.
Сразу признаюсь, что ни разу не применял его и не встречал в проектах.
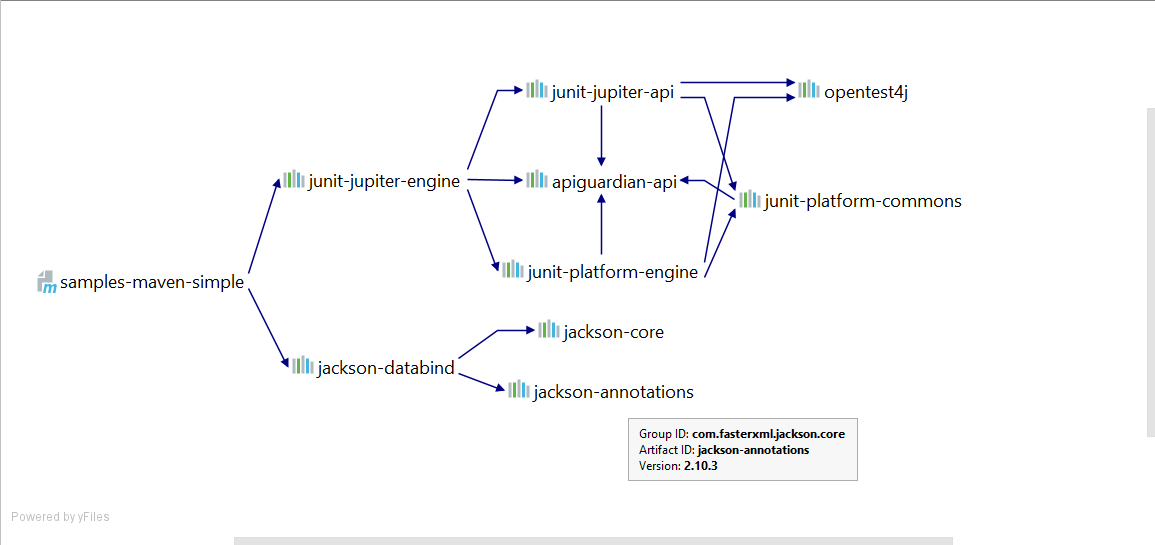
В pom.xml мы добавили только зависимость на jackson-databind, но по факту используются ещё и jackson-annotations и jackson-core.
Это происходит из-за механизма транзитивных зависимостей. Посмотреть весь граф зависимостей можно в IDEA по комбинации клавиш Ctrl+Alt+Shift+U при открытом pom.xml.
Возможно, что это работает только в IDEA Ultimate. В этом окне работает поиск по Ctrl+F, поэтому если Вы пытаетесь выяснить,
откуда же просачивается какая-то библиотека, то это очень удобный и полезный инструмент.
Если нам по какой-то причине нужно избавиться от транзитивной зависимости, то исключить её можно при помощи exclusion.
Чаще всего это применяется к библиотекам логирования. Например, исключаем отовсюду log4j, а потом добавляем log4j-over-slf4j.
Подробнее тут.
Добавлю один интересный сценарий связанный с тестированием, о котором не все знают. Все тесты располагаются в папке src/test,
в все юнит тесты имеют постфикс "Test". По практикам разработки существуют ещё интеграционные тесты, которые могут использовать внешние сервисы и запускаются отдельно от юнит тестов.
Для них иногда заводят отдельные модули и настройки surefire плагина. Можно поступить иначе - добавить к имени теста постфикс "IT" (полный список: **/IT*.java, **/*IT.java, **/*ITCase.java).
Такие тесты запускаются командой "mvn verify", а отвечает за них специальный maven-failsafe-plugin. Он требует явного указания в pom.xml:
Запуск интеграционных тестов включает запуск юнит тестов, но не наоборот. Хотя есть запускать тесты через IDEA командой "Run all in...", то выполнится оба типа тестов, поэтому речь идёт
о работе непосредственно через команду mvn. Можно пользоваться таким лайфхаком: если у вас получился полезный тест, но как юнит он не годится,
то можно перед коммитом не комментировать и не выключать его аннотациями @Disabled (Junit 5) или @Ignore (Junit 4), а просто переименовать в *IT.
Наверное, этот пост будет бесконечным. Мы работаем с тривиальным приложением, состоящим из одного модуля, но пока что рассмотрели лишь простую сборку и запуск при условии, что всё шло хорошо.
У меня включен интернет, нет никаких прокси серверов и зеркал maven репозиториев. Пользовательская директория в Windows находится там где обычно, а не где-нибудь на сетевом диске.
В Windows отсутствуют корпоративные политики и ограничения.
Я попробую рассказать о проблемах, которые могут возникать в связи с вышеперечисленными ограничениями, но не буду пытаться воспроизвести их все.
Представим конфигурацию, когда maven работает не непосредственно с центральным maven репозиторием, а через корпоративный Nexus или Artifactory.
Первое, что нам понадобится - указать пользовательские настройки для Maven в файле .m2/settings.xml.
Частая проблема, что файл настроен правильно, но находится не там, где его ищет Maven.
При любых проблемах и подозрениях запускаем Maven с параметром -X, включающим подробное логирование процесса сборки:
mvn clean package -X
В выводе ищем settings.xml:
[DEBUG] Reading global settings from C:\Program Files\JetBrains\IntelliJ IDEA 2019.3.1\plugins\maven\lib\maven3\conf\settings.xml
[DEBUG] Reading user settings from C:\Users\HiPravin\.m2\settings.xml
Обычно настраивают пользовательскую конфигурацию, а глобальную не трогают.
Таким образом правильный путь к файлу настроек - это "C:\Users\HiPravin\.m2\settings.xml".
В этом файле для нас могут быть критичными настройки прокси, если он используется для доступа к сети, а также mirror репозитории.
Mirror означает, что для поиска jackson бы обращаемся к нашему внутреннему серверу Artifactory, а он уже сам как-то выкачивает зависимости из центрального репозитория и имеет доступ в интернет.
В целом Maven хорошо приспособлен для работы как без интернет, так и вообще без сети (чего не скажешь о gradle).
Пример понфигурации прокси:
Пример конфигурации зеркал. С этими настройками возникает ряд сложностей - например, загружаются зависимости, но не загружаются плагины, либо
за внутренними артефактами всё равно идём в центральный репозиторий. Но эти проблемы очень специфичны и пример привести я не могу.
Обычно в компаниях однократно создают рабочий файл настроек, а потом передают его всем новым сотрудникам по необходимости.
<mirrors><mirror><id>internal-repository</id><name>Maven Repository Manager running on repo.mycompany.com</name><url>http://repo.mycompany.com/proxy</url><mirrorOf>*</mirrorOf></mirror></mirrors>
Внутренние репозитории указываются в секции repositories и pluginRepositories.
Правильные настройки в settings.xml позволяют достичь стабильной работы в условиях всех ограничений.
Рассмотрим ещё один не совсем стандартный сценарий. Предположим, что какой-то библиотеки нет в ни в центральном репозитории, ни в во внутреннем (если он используется).
Не важно по какой причине - может быть мы создали пропатченную версию jackson библиотеки. Если библиотека уже находится в папке .m2/repository,
то Maven будет её использовать, даже если в удалённых репозиториях её нет. Содержимое этой папки иногда называют локальным репозиторием Maven'а.
Просто скопировать файл нельзя, потому что вместе с ним должны находиться метаданные, включающие контрольную сумму и результат последней попытки загрузки.
Можно использовать команду install:install-file, например, так:
При этом теряются все зависимости, потому что никто никогда не указывает pom файл (-DpomFile=<path-to-pomfile>).
Так можно устанавливать сторонние библиотеки, но для артефактов сборки проекта следует использовать install по умолчанию:
mvn clean install
В этом случае pom файл, зависимости, координаты (group id, artifact id, version), снепшот/релиз - всё будет определено автоматически и правильно.
Для более точной демонстрации того, о чём пойдёт речь дальше, понадобился локально запущенный Sonatype Nexus.
Для его установки я загрузил архив, распаковал и запустил "nexus.exe /run", как показано по этой ссылке.
Затем я установил пароль администратора на password1 и создал два репозитория:
samples-snapshots и samples-releases, как описано здесь.
Давайте вспомним, какими командами мы до сих пор собирали проект и добавим ещё одну.
package
Собирает проект, запаковывает в JAR/WAR/EAR, помещает в директорию target
install
Выполняет package и устанавливает артефакт сборки в локальный репозиторий Maven. Упрощённо - копирует в директорию .m2/repository.
deploy
Выполняет package, install и загружает (upload) результат на удалённый репозиторий Maven.
Как вы поняли, речь идёт о команде deploy. Если в текущей конфигурации проекта запустить деплой, то получим такую ошибку:
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-deploy-plugin:2.7:deploy (default-deploy)
on project samples-maven-simple: Deployment failed: repository element was not specified in the POM
inside distributionManagement element or in -DaltDeploymentRepository=id::layout::url parameter -> [Help 1]
Нужно указать путь к серверу, на который мы будем отправлять результат сборки нашего проекта. По умолчанию файлы не будут загружаться в центральный репозиторий,
да и вообще крайне маловероятно, что мы будем когда-либо его для этого использовать. Поэтому теперь точно понадобится локальный или корпоративный сервер Nexus или Artifactory.
Кроме адреса сервера понадобится ещё логин и пароль, потому что загружать артефакты без авторизации запрещено.
Эти данные нужно внести в pom.xml:
В pom.xml мы не можем указать логин и пароль, потому что подобные чувствительные (sensitive) данные никогда не должные попадать в систему контроля версий.
Вместо этого мы указываем id, работающий как ссылка на запись в settings.xml. В settings.xml нужно добавить секцию servers:
Теперь запуская "mvn deploy" файлы будут загружаться на сервер http://localhost:8081/ и станут доступными всем авторизованным пользователям этого репозитория.
Maven central - публичный сервер, доступный на чтение всем без ограничений, но в корпоративном сервере Artifatory возможно настраивать гранулярные права доступа.
Уже несколько раз всплывают некие "релизы" и "снэпшоты", пришло время подробнее поговорить и о них, тем более что это одна из центральных идей Maven.
Версия, которая указывается в pom.xml в теге version - это не просто строка, принимающее произвольное значение, служащее идентификатором.
Процесс деплоя и загрузки напрямую зависит от того, заканчивается ли версия подстрокой "-SNAPSHOT". Если это так, то версия является "снэпшотной", а иначе - "релизной".
Сначала рассмотрим релизные версии, так как их поведение более привычно для всех.
В нашем мини проекте меняем версию на 1.0 и запускаем "mvn deploy" дважды. В первый раз всё загружается на сервер, но во второй раз загрузка прерывается с ошибкой 400.
Uploading to sample-releases: http://localhost:8081/repository/sample-releases/hipravin/samples/samples-maven-simple/1.0/samples-maven-simple-1.0.jar
Uploaded to sample-releases: http://localhost:8081/repository/sample-releases/hipravin/samples/samples-maven-simple/1.0/samples-maven-simple-1.0.jar (3.6 kB at 2.6 kB/s)
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-deploy-plugin:2.7:deploy (default-deploy)
on project samples-maven-simple: Failed to deploy artifacts:
Could not transfer artifact hipravin.samples:samples-maven-simple:jar:1.0 from/to sample-releases
(http://localhost:8081/repository/sample-releases/): Failed to transfer file
http://localhost:8081/repository/sample-releases/hipravin/samples/samples-maven-simple/1.0/samples-maven-simple-1.0.jar
with status code 400 -> [Help 1]
По факту это произошло потому, что в настройках репозитория samples-releases я установил "Deployment Policy" в значение "Disable Redeploy".
Но по смыслу именно так задуманы релизные версии, и так всегда настраивают Nexus или Artifactory. То есть релизную версию можно загрузить лишь один раз.
Поэтому любое приложение, указавшее зависимость на нашу библиотеку в будущем может быть уверено, что содержимое этой библиотеки никогда не изменится.
Если мы внесём исправление, то придётся инкрементировать версию приложения: 1.0.1, 1.1, 1.0.patched и повторять деплой.
Зависимость может быть указана вот так, в этом плане наше приложение ничем не отличается от библиотек, которые мы используем:
Деплой в Maven репозиторий должен осуществляться с сервера CI (Jenkins/TeamCity) и никогда - с локальной машины разработчика.
Если мы будем пользоваться релизными версиями во время цикла разработки, пока версия кода ещё далека от финальной,
и каждый день вносятся изменения, то нас ждут два неприятных эффекта: первый - история коммитов будет как минимум наполовину состоять из изменённых версий,
второй - удалённый maven репозиторий будет забиваться большим количеством заведомо нерабочих версий.
Справедливо сказать, что оба этих эффекта неприемлемы, поэтому в период, когда требуются частые изменения, используют снэпшотные версии.
Итак, снэпшотные версии. Что же это за зверь такой? У таких версий имя должно оканчиваться на '-SNAPSHOT', давайте поменяем нашу версию в pom.xml обратно на 1.0-SNAPSHOT,
а потом несколько раз запустим "mvn deploy".
Uploading to sample-snapshots: http://localhost:8081/repository/sample-snapshots/hipravin/samples
/samples-maven-simple/1.0-SNAPSHOT/samples-maven-simple-1.0-20200409.090535-1.jar
...
Uploading to sample-snapshots: http://localhost:8081/repository/sample-snapshots/hipravin/samples
/samples-maven-simple/1.0-SNAPSHOT/samples-maven-simple-1.0-20200409.091006-2.jar
...
Uploading to sample-snapshots: http://localhost:8081/repository/sample-snapshots/hipravin/samples
/samples-maven-simple/1.0-SNAPSHOT/samples-maven-simple-1.0-20200409.091101-3.jar
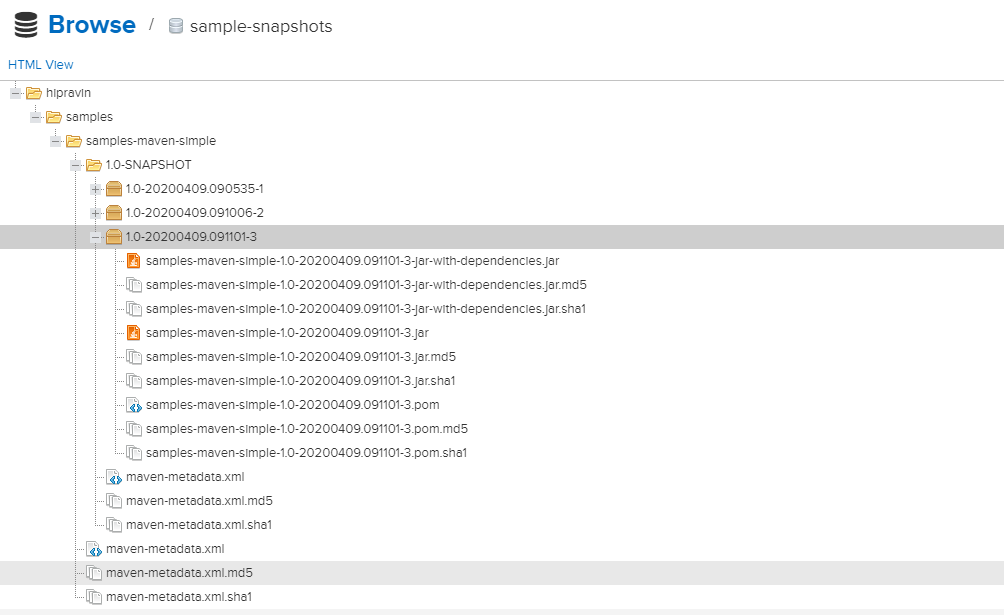
Версия 1.0-SNAPSHOT автоматически заменяется на уникальную строку с указанием даты, времени и порядкового номера.
В старой версии Maven (maven2, 2014-02-18 End of Life) можно было отключить такую подстановку, но это сочли не рекомендуемой и порочной практикой.
При этом в секции зависимостей так же должна быть 1.0-SNAPSHOT и никак не 1.0-20200409.091101-3. Таким образом,
процесс деплоя и загрузки содержит в себе неявное преобразование версии. Кроме того загружая версию из репозитория несколько раз мы можем получать разные результаты.
Единственный способ посмотреть, какие были версии на самом деле загружены - воспользоваться интерфейсом репозитория, пример ниже на скриншоте.
Предположим, что мы одновременно исправляем библиотеку и основное приложение, при этом полностью проверить библиотеку в отрыве от основного приложения невозможно.
После коммита в код библиотеки вы выполняем deploy с версией snapshot,
а потом проверяем основное приложение с обновленной библиотекой. В этот момент возникает неопределённость, связанная с тем, что снэпшоты не загружаются при каждой сборке.
Параметры обновления настраиваются в файле settings.xml, параметр updatePolicy:
always - always check when Maven is started for newer versions of snapshots
never - never check for newer remote versions. Once off manual updates can be performed.
daily (default) - check on the first run of the day (local time)
interval:XXX - check every XXX minutes
То есть при настройках по умолчанию придётся ждать целый день, чтобы воспользоваться исправленной версией библиотеки!
А если установить опцию 'always', то сборки начнут заметно тормозить при большом количестве snapshot зависимостей.
Удобно при необходимости добавлять к аргументам команды сборки параметр "-U" (mvn clean package -U), тогда все снэпшоты будут принудительно обновлены.
Процесс разработки можно выстроить следующим образом:
Устанавливаем версию библиотеки 1.0-SNAPSHOT
Устанавливаем версию зависимости в основном приложении в 1.0-SNAPSHOT
Вносим изменения в библиотеку, выполняем deploy
Пересобираем основное приложение, при необходимости с аргументом -U, тестируем
Повторяем шаги 3-4 до тех пор, пока код не стабилизируется и все ошибки не будут исправлены
Устанавливаем версию библиотеки 1.0
Устанавливаем версию зависимости в основном приложении в 1.0
Осуществляем финальные проверки и выходим в релиз. Если находим ошибки, возвращаемся на шаг 6, меняя версию на 1.0.1
Начинаем работу над следующим релизом
Устанавливаем версию библиотеки 1.1-SNAPSHOT
Устанавливаем версию зависимости в основном приложении в 1.1-SNAPSHOT
Чтобы снэпшоты не накапливались в репозитории в неограниченном количестве, в Nexus и Artifactory существуют политика удаления старых версий.
Поэтому иногда старые снэпшоты теряют свою актуальность или вообще пропадают из репозитория, хотя по хорошему последняя-то версия не должна удаляться.
Следует руководствоваться следующим правилом: версия release не должна иметь snapshot зависимостей.
Только в этом случае релизная версия представляет собой что-то финальное и не подверженное случайным факторам.
Если же мы оперируем версиями snapshot, значит наш код часто меняется и при случае мы легко можем восстановить артефакт в репозитории, запустив команду deploy.
На этом пока оставим релизы и снэпшоты. Заметили, что вместе с обычным артефактом сборки в репозиторий попала ещё версия "jar-with-dependencies"?
При этом группа, артефакт и версия у них совпадают. Это возможно благодаря дополнительному атрибуту зависимостей - classifier.
При использовании assembly плагина в файле конфигурации assembly.xml нужно указать id. В нашей сборке id неявно устанавливается в "jar-with-dependencies".
Результаты сборки плагином assembly ведут себя так же, как и основной артефакт. Зависимость будет выглядеть так, если понадобится:
Атрибут classifier также используется при загрузке исходного кода и документации javadoc.
По умолчанию загружается только скомпилированный код, а пользователи нашей библиотеки не увидят никакой документации,
а если попытаются посмотреть исходный код, то получат в лучшем случае декомпилированную версию. Это не очень удобно, поэтому лучше
публиковать sources и javadoc. Для этого добавляем в pom.xml два плагина:
Теперь при выполнении команды deploy в репозиторий будут загружены дополнительные артефакты с классификаторами "-sources" и "-javadoc", и
соответствующая информация будет автоматически доступна в IDE разработчика, использующего нашу библиотеку.
Модули
До сих пор мы работали с приложением, состоящим из одного модуля. Однако модули - едва ли не главная функциональность Maven,
сильнее всего влияющая на процесс проектирования и разработки приложений.
Сегодня в эпоху микросервисов становится всё более популярно использовать один репозиторий (GIT) для одного сервиса.
В этом случае объём кода и логики одного приложения часто не требует разделения на модули. Сейчас я не буду никак сравнивать монолит с микросервисной архитектурой.
Многие работают с монолитом или как минимум c приложениями с большим объёмом кода в одном репозитории.
В этом случае разделение кода на модули имеет тот же смысл, что разделение на пакеты, классы, методы.
Разделение на пакеты - по большей части логическое, визуальное, если не считать модификаторов доступа protected и default.
При разделение на модули код одного модуля ни во время компиляции, ни во время исполнения ничего не знает о других модулях, если не установлена зависимость.
Одна из ситуаций, когда модули жизненно необходимы - если в одном проекте уживаются вместе несколько приложений.
Например, несколько web приложений, которые мы собираем в отдельные WAR архивы и может даже развертываем на разных серверах Apache Tomcat.
Каждое приложение мы помещаем в отдельный модуль. Приложения не полностью различны, они как-то перекликаются, относятся к единому бизнес домену, поэтому
возникают повторяющиеся классы и методы, то есть дублирование кода. Тогда мы выделяем отдельный модуль common, куда перемещаем все общие части.
Потом нам хочется больше модулей, чтобы каждый отвечал за свою задачу, а не содержал сборную солянку разных утилит.
Тогда в дополнение к common мы вводим модули security, model, dao и так далее. Просто чтобы в коде было чисто и аккуратно.
Бонусом получаем скорость сборки, ведь нет смысла пересобирать модули, в которых не было изменений.
Код примера.
Рассмотрим небольшое приложение, состоящее из нескольких модулей.
Программа подсчитывает частоту появления различных слов во входном файле.
В модуле common реализован сам алгоритм, модуль consoleapp содержит главный класс для запуска из консоли, а модуль webapp - Web приложение с REST сервисом.
Между webapp и сonsoleapp нет зависимостей, но оба зависят от common.
Можно представить, что приложение существует давно, а для работы с ним всегда использовалась консоль, но
теперь решили добавить ещё и веб сервис. В коде приложения ничего показательного, его я приводить не буду, лучше сконцентрируюсь на Maven.
При создании проекта в корне я сразу удалил папку src, а в pom.xml установил свойство packaging в значение "pom".
Также artifactId имеет окончание "-parent", но это необязательно, больше для удобства и потому что так принято.
Такой модуль называют родительским (parent) или иногда основным, главным. Он обычно не содержит исходного кода и артефактов сборки.
Его предназначение - управлять остальными модулями. Все они должны быть перечислены в теге modules:
Все дочерние (child) модули наследуют свойства, зависимости, плагины от родительского модуля.
Например, уровень языка для compiler плагина достаточно указать только в главном модуле.
А вот зависимости в главном модуле указывать не стоит, потому что исключить их в дочерних модулях будет крайне затруднительно.
Вместо этого в родительском модуле фиксируют список библиотек их версий, а в дочерних - лишь ссылаются на них. Выглядит это так:
в главном модуле в pom.xml используется тег dependencyManagement, а в дочерних - dependency без версии:
Помимо перечисления версий библиотек в dependencyManagement по одной, существует дополнительный механизм
указания версий для целой группы зависимостей - BOM (Bill Of Materials).
Это очень полезно для проектов с большим количеством модулей (например, для spring: core, context, beans, web, jdbc, ...).
Модуль webapp использует Spring Boot, BOM можно указать в главном модуле следующим образом:
<!--./pom.xml--><dependencyManagement><dependencies><dependency><!-- Import dependency management from Spring Boot --><groupId>org.springframework.boot</groupId><artifactId>spring-boot-dependencies</artifactId><version>2.2.6.RELEASE</version><type>pom</type><scope>import</scope></dependency>
...
</dependencies></dependencyManagement><!--./webapp/pom.xml--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency>
Ключевым здесь является значение параметра scope равное import.
Для проектов, использующих Spring Boot альтернативный вариант - указать в качестве родительского проекта spring-boot-starter-parent.
То есть родительский модуль не обязательно должен располагаться рядом в том же проекте, он может загружаться и из удалённого Maven репозитория.
В этом случае нужно установить свойство relativePath в пустое значение. Например, так:
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.2.2.RELEASE</version><relativePath/><!-- lookup parent from repository --></parent>
При этом родительский модуль может быть только один.
Чтобы классы из модуля common были доступны в модуле consoleapp, нужно добавить зависимость так же,
как ранее мы добавляли зависимость на библиотеку jackson.
Вместо версии 1.0-SNAPSHOT мы ссылаемся на версию родительского модуля, потому что неразумно иметь разные версии в рамках одного проекта,
а дублировать эту версию многократно неудобно. На этом этапе может возникнуть определённая путаница, как в понимании происходящего, так и в работе самого Maven.
Как мы знаем, зависимости загружаются из репозитория, либо берутся напрямую из папки .m2.
Но мы ещё ни разу не собирали наш проект и тем более не выполняли install или deploy. В рамках одного проекта Maven в этом не нуждается - он выстроит дерево зависимостей наших модулей,
причём именно дерево, а не граф, потому что циклы запрещены. Потом он осуществит сборку модулей в правильном порядке и при работе с каждым модулем все его зависимости уже будут обработаны.
Если какой-то из модулей Maven упорно пытается искать в репозитории, то вероятно допущена ошибка в координатах зависимости.
Чтобы собрать весь проект целиком достаточно запустить команду "mvn package" в корне проекта. Так же с install и deploy.
Так выглядит лог успешной сборки:
Довольно редко возникает необходимость собирать только один модуль, однако если проект громоздкий
и полный билд занимает минуты, то это может быть полезно. Для этого нужно указать список модулей для сборки, например один модуль webapp,
а также параметр --also-make, чтобы были обработаны необходимые модули, от которых явно или неявно зависит webapp.
Заметим, что сейчас в проекте несколько раз дублируется версия родительского модуля.
Это вполне допустимо, но при обновлении версии на, скажем, 1.0 или 1.1-SNAPSHOT, нам придётся обновлять код в нескольких местах,
что создаёт вероятность ошибки, вызванной человеческим фактором. Хуже всего обновлять по памяти: тут, тут и тут,
потому что легко можно случайно забыть или пропустить один из модулей.
Если артефакты попадают в локальный репозиторий, то проект продолжит собираться без ошибок, но код одного из модулей будет использовать старую версию родительского модуля.
Второй вариант - использовать автозамену по проекту (Ctrl+Shift+R в IDEA). Этот вариант плох тем, что можно случайно заменить лишнего - но чаще всего в этом случае
проект просто не скопмилируется. Правильный способ обновлять версию - использовать плагин versions:
Команда "commit" здесь не имеет ничего общего с коммитом в системе контроля версий, это специфический этап работы плагина,
удаляющий сохранённую копию pom.xml файла, которая создаётся на первом этапе.
Разное
О нескольких моментах стоит упомянуть для полноты картины, хоть им не нашлось места в демонстрационных проектах, описанных ранее.
Параметр optional. Модули webapp и consoleapp транзитивно зависят от всех библиотек, от которых зависит common.
Эти библиотеки можно исключить в pom.xml каждого из этих модулей, используя exclusions, как мы уже видели.
Альтернативно можно указать на этих зависимостях в модуле common параметр optional в значение true,
тогда в webapp и consoleapp изменения не потребуются.
Используется редко, не буду заострять внимание на этом.
Беспорядок с версиями зависимостей. Версия одной и той же библиотеки может быть указана явно единожды, транзитивно единожды, явно многократно, транзитивно многократно.
Теоретически у Maven есть детерминированный алгоритм по определению версии.
Практически лучше избегать неопределённости и изучать граф зависимостей, а также список библиотек, попадающий в артефакт сборки
JAR with dependencies, WAR или EAR. Версия, указанная явно в pom.xml самого модуля имеет приоритет над транзитивными версиями.
Однако если версии отличаются ещё и в group id / artifact id как, например, log4j и log4j2, то проблему можно решить только аккуратным исключением всех лишних зависимостей.
А найти проблему можно, опять же, только анализом графа зависимостей и артефактов сборки.
Dependency scope. Для каждой зависимости можно указать scope. Часть значений влияет на то, в какие classpath попадает данная зависимость,
другие просто определяют некое особое поведение.
Мы уже встречали compile (значение по умолчанию), test и import. Я просто приведу список всех значений с небольшими комментариями. Я буду писать "сохраняется в lib" имея в виду, что
библиотека попадает в classpath во время исполнения, а также копируется в директорию lib внутри артефактов сборки таких как WAR и EAR.
compile
Значение по умолчанию. Зависимость доступна во время компиляции основного кода и тестов, сохраняется в lib.
provided
Зависимость доступна во время компиляции основного кода и тестов, но не сохраняется в lib.
Применяется, когда библиотека предоставляется контейнером. Например, Weblogic предоставляет драйвер для соединения с базой данных.
runtime
Зависимость не доступна во время компиляции основного кода, доступна для компиляции тестов (не знаю зачем), но сохраняется в lib.
Пример - драйвер базы данных, библиотеки логирования.
test
Зависимость не доступна во время компиляции основного кода, доступна для компиляции тестов, не сохраняется в lib.
system
Позволяет подключить библиотеку, jar файл которой располагается по определённому пути на файловой системе.
Не рекомендую к использованию, в этом случае следует просто установить библиотеку в локальный репозиторий с помощью install-file.
import
Используется в dependencyManagement вместе c так называемым BOM (bill of materials)
Я не разбираю scope подробно, потому что в большинстве случаев достаточно compile и test, которые тривиальны, а остальные применяются по ситуации и
редко приводят к скрытым ошибкам. А вот понять и запомнить чем отличается provided от runtime при первом знакомстве мало кому удаётся.
Жизненный цикл, фазы.
Жизненный цикл состоит из фаз, которые мы можем указывать в строке запуска mvn.
Каждый плагин запускается в ту фазу, которая указана в его конфигурации.
Список всех фаз: validate, compile, test, package, verify, install, deploy.
Опять же углубляться не буду, полагаю станет только непонятней.
С практической точки зрения мы уже рассмотрели все основные фазы жизненного цикла.
Архетипы.
Без использования IDE чтобы создать пустой maven проект нужно будет где-то взять заголовок xml файла и добавить в него как минимум координаты проекта.
А если наш проект использует какой-то фреймворк, то потребуются ещё какие-нибудь обязательные настройки и файлы. В Maven существует понятие архетипа -
способа создавать готовые проекты по шаблону с указанием набора параметров.
Spring initializer, вероятно, внутри работает на основе архетипов. Однако это отдельный сайт, да и ещё со встроенной поддержкой в IDEA, поэтому пользоваться шаблонами Spring Boot
через интерфейс командной строки было бы странно.
В своей практике я не применял архетипы кроме как в ознакомительных целях.
Gradle. Gradle - аналог Maven, который появился чуть позже и считается более продвинутым, современным, стильным - модным - молодежным.
Основное различие между ними - Gradle использует язык Groovy или Kotlin для конфигурации, а не XML, а также по-другому определяет жизненный цикл.
Одно и то же приложение может одновременно иметь эквивалентные конфигурации сборок на Maven и Gradle.
На сайте spring.io примеры одновременно содержат инструкции и для Maven, и для Gradle.
При этом сам springframework начиная как минимум с версии 4 собирается с помощью Gradle.
В работе же я встречал только Maven, если не считать одного приложения, которое потом перенесли на Maven для порядка и потому что Gradle билд сломался, а починить никто не сумел.
По своему опыту могу только сказать, что Gradle очень плохо настраивается в окружении, где отсутствует или ограничен доступ в интернет.
Не исключено, что при должной сноровке это возможно, но у кого она есть, эта сноровка.
Я уверен, что в коммерческой разработке Maven ещё долго будет популярен благодаря старым проектам и наработанному специалистами опыту.
Заключение
В Mаven очень много нюансов и тонкостей, но в целом это очень стройная и эффективная технология и экосистема.
Так или иначе, в мире Java разработки встречи с Maven не избежать.
Надеюсь, что наиболее частые, полезные и хитрые сценарии я как-нибудь, да затронул.