Заметки о java.util.Stream
Stream API (поток) - принципиально новый способ работы с коллекциями в Java. Вернее, так было во времена релиза Java 8 в далёком 2014 году, который принёс в классический императивный объектно-ориентированный язык программирования элементы функционального программирования. Ввиду масштаба нововведений сначала перед разработчиками стояла задача изучить новые подходы и наработать опыт их применения. После первого знакомства возник соблазн применять функциональный стиль в любой возможной ситуации, даже если в итоге получались сложные причудливые и никому не понятные конструкции. Тогда могло возникнуть обратное желание - отказаться от всех новшеств, если в них нет очевидной необходимости. В данной статье я опишу отдельные примеры использования Stream, которые кажутся мне наиболее интересными и показательными, чтобы применять Stream API эффективно, делая код лучше и избегая ошибок.
Основы и мотивация
Лучшим введением в потоки был бы перевод этой обучающей статьи с сайта Oracle. Однако, это слишком громоздко и, в целом, не нужно. Я предполагаю, что читатель уже знаком с потоками и имеет определённый опыт их применения. Я приведу вольный перевод основных тезисов, которые будут полезны для дальнейших примеров.
- Почти каждое приложение работает с коллекциями: поиск, выбор элементов, трансформации, сортировки, поиски максимальных значений, агрегации. Несмотря на свою значимость и вездесущность, работа с коллекциями в Java далека от идеала. Приходится многократно реализовывать типовые алгоритмы с использованием циклов и условных операторов.
- Использование многоядерной архитектуры для ускорения работы с большими коллекциями требует написания сложного многопоточного кода, подверженного ошибкам.
- Потоки - новая абстракция, добавленная в Java 8, призваны решить эти и многие другие проблемы. Во-первых, они позволяют писать код в декларативном стиле. Во-вторых, позволяют использовать параллельные вычисления без написания многопоточного кода.
Также в статье сравнивается код, написанный с использованием разных подходов. Он решает задачу выборки определённых транзакций с последующей сортировкой и получением списка идентификаторов.
Классический подход:
List<Transaction> groceryTransactions = new Arraylist<>();
for(Transaction t: transactions){
if(t.getType() == Transaction.GROCERY){
groceryTransactions.add(t);
}
}
Collections.sort(groceryTransactions, new Comparator(){
public int compare(Transaction t1, Transaction t2){
return t2.getValue().compareTo(t1.getValue());
}
});
List<Integer> transactionIds = new ArrayList<>();
for(Transaction t: groceryTransactions){
transactionsIds.add(t.getId());
}
}
Реализация с использованием потоков:
List<Integer> transactionsIds = transactions.stream()
.filter(t -> t.getType() == Transaction.GROCERY)
.sorted(comparing(Transaction::getValue).reversed())
.map(Transaction::getId)
.toList();
Теперь только потоки?
Пожалуй, всё это звучит чересчур оптимистично.
Пример задачи и её реализации, в котором объём кода уменьшается в два-три раза достаточно искусственный.
Использовать достоинства параллельных вычислений, избегая недостатков, таких как сложность реализации и трудноуловимые ошибки - наивно.
Может быть это больше стремление идти в ногу со временем, сделать язык более современным?
Java сообщество давно требовало элементов функционального программирования. Кто-то перешёл на Scala, вдохновлённый лаконичностью и выразительностью функционального кода.
Многие стали активно применять библиотеку guava, которая позволяет написать, например, такой код:
//Доступно с 12 версии, опубликованной 30 апреля 2012 года
List<String> results =
FluentIterable.from(database.getClientList())
.filter(activeInLastMonthPredicate)
.transform(Functions.toStringFunction())
.limit(10)
.toList();
Автозаполнение (autocomplete) для почтовых индексов
Сформулируем следующую задачу: осуществить подсказки и проверку ввода при заполнении поля с почтовым индексом.
Такая задача может возникнуть во многих приложениях, в которых требуется указать адрес пользователя.
Удобным и современным решением является поиск значений "на лету" по части введенного значения и вывод короткого списка подходящий значений.
Решать задачу будем от этапа получения данных от источника до функции, возвращающей результат поиска.
Отображение результата пользователю не входит в требования - это может быть сайт, десктопное или мобильное приложение.
Конечным результатом будет функция, возвращающая список индексов, начинающихся с заданного префикса, ограниченный заданным размером:
List<PostIndex> findByIndexStartingWith(String prefix, int limit);
Эталонный справочник почтовых индексов объектов почтовой связи можно найти в открытом доступе на сайте Почты России. В нём чуть меньше 60 000 записей и распространяется он в одном файле в формате DBF. Многие разработчики не сталкиваются с данным форматом данных, сейчас более привычным был бы какой-нибудь REST сервис. Для проектирования решения задачи о данном формате нужно знать следующее:
- Файл состоит из заголовка и набора строк, каждая из которых содержит всю информацию о почтовом индексе.
- Для каждого индекса кроме самого цифрового кода присутствуют несколько текстовых полей, описывающих адрес, таких как район, город, автономная область.
- Файл возможно читать построчно. Звучит очевидно, но если все данные, например, сохранить в единый JSON объект, то извлекать данные до загрузки всего файла было бы проблематично.
- Данные меняются редко. Вероятно не чаще раза в сутки, а обычно раз в неделю и реже.
Стандартное решение данной задачи - загружать файл с индексами ежедневно в корпоративную базу данных, в которой индексы представлены отдельной таблицей, например, POST_INDEX.
В этом случае выбор данных будет осуществляться простым запросом наподобие такого:
select * from POST_INDEX
where index like '1017%'
order by index
limit 10 ;
Выделим два интерфейса для решения поставленной задачи:
- Первый отвечает за загрузку данных из файла и преобразование к доменной модели.
public interface PostIndexReader { //Вариант 1 - стрим Stream<PostIndex> readAll(); //Вариант 2 - список List<PostIndex> readAllList(); //Вариант 3 - обработчик, который будет вызван на каждый элемент если запись соответствует указанному условию void readAll(Predicate<? super PostIndex> acceptPostIndex, Consumer<? super PostIndex> handler); //Другие варианты, например, Visitor паттерн ... } - Второй - аналог DAO, отвечает за хранение и методы доступа к данным.
Детали хранения будут выбраны в реализации, интерфейс фиксирует только контракт доступа к данным.
public interface PostIndexRepository { List<PostIndex> findByIndexStartingWith(String prefix, int limit); }
Желательно спроектировать систему так, чтобы она выдерживала определённый рост нагрузки и объёма данных. Stream в качестве возвращаемого значение позволяет достичь сразу нескольких целей:
- Экономия памяти, потому что не нужно формировать список всех записей исходного файла. Позволяет работать с файлами большого размера.
- Возможность не вычитывать файл целиком. Например, если нам нужен только московский регион, и он расположен в начале файла, то оставшуюся часть файла можно игнорировать. Достаточно при обработке потока применить метод takeWhile (например, .takeWhile(pi -> "МОСКВА".equals(pi.region());)
- Параллелизм. В общем да, но в данном случае нет. Если бы данные приходили из нескольких файлов, то можно было бы разделить обработку по файлам. Даже если обрабатывать один файл в несколько потоков и возможно теоретически, то библиотека для работы с файлами DBF точно на такое не рассчитана.
Чтобы без использования потоков достичь первой цели можно передать в качестве параметров обработчик и (необязательно) условие фильтрации записей (вариант 3 в листинге выше).
Достичь одновременно первых двух целей можно с помощью паттерна Посетитель (Visitor). Пример этого паттерна - обход файлового дерева. Но для обхода строк в одном файле данный подход явно избыточен.
Что ж, для начала реализуем чтение записей в список:
@Override
public List<PostIndex> readAllList() {
List<PostIndex> result = new ArrayList<>();
try (BufferedInputStream bis = new BufferedInputStream(Files.newInputStream(indexFilePath));
DBFReader reader = new DBFReader(bis)) {
DBFRow dbfRow;
while ((dbfRow = reader.nextRow()) != null) {
result.add(postIndexRowMapper.map(dbfRow));
}
} catch (IOException e) {
throw new UncheckedIOException(e);
}
return result;
}
Должно быть несложно преобразовать такой код так, чтобы возвращаемым результатом стал поток. Или нет?
Давайте порассуждаем. Ради шутки можно просто получить поток из готового списка:
return readAllList().stream(); //"тот же список, только в профиль"
Создание потоков
Начнём с перечисления самых простых и часто используемых способов и оценим, насколько они подходят для решения нашей задачи.
1. Пустой поток можно создать вызовом Stream.of() или Stream.empty():
Stream<String> emptyStream1 = Stream.of();
Stream<String> emptyStream2 = Stream.empty();
2. Поток из фиксированных элементов можно создать с помощью метода Stream.of(...):
Stream<String> someLetters = Stream.of("a", "b", "c");
3. Поток из фиксированных элементов можно создать также в помощью класса Stream.Builder:
Stream<String> someLetters = Stream.<String>builder()
.add("a").add("b").add("c")
.build(); или так:
Stream.Builder<String> builder = Stream.builder();
builder.accept("a");
builder.accept("b");
builder.accept("c");
Stream<String> someLetters = builder.build(); Такой способ может быть альтернативой созданию потока из ArrayList. Реализация Stream.Builder использует SpinedBuffer, который вместо одного большого массива, содержащего все элементы использует массив массивов. Такая реализация не требует непрерывной области памяти, в которую бы поместились все элементы, что в теории упрощает управление памятью и снижает нагрузку на сборщик мусора. На практике такой способ создания потоков используется редко.
4. Метод Stream.iterate(...) позволяет создавать потоки, в которых следующий элемент можно получить из предыдущего.
Нужно задать начальный элемент и функцию получения следующего элемента (UnaryOperator).
Дополнительно можно указать условие конца итерации.
Например, получим поток дат (LocalDate) на 7 дней вперёд, а также поток дат до конца месяца:
Stream<LocalDate> oneWeekForward = Stream.iterate(today, d -> d.plusDays(1))
.limit(7);
Stream<LocalDate> datesTillEndOfMonth =
Stream.iterate(today, d -> d.getMonth() == today.getMonth(), d -> d.plusDays(1));
Перед тем, как пойти дальше, добавлю важное замечание касательно Stream.iterate.
Интуитивно понятно, что такой поток нельзя обработать параллельно, так как мы не можем получить следующий элемент, не обработав предыдущий.
Программа даже не знает, нужен ли следующий элемент вообще, может быть поток надо завершить из-за наступления условия, указанного параметром в takeWhile.
Так вот, это "интуитивное утверждение" полностью ошибочно. Работая с потоками, следует избегать предположений о том, как код скорее всего работает, а вместо
этого аккуратно следовать спецификации, указанной в документации. Никаких указаний на то, что к потоку,
порождённому методом Stream.iterate нельзя применить вызов функции .parallel() нет.
Давайте запустим такую программу, которая порождает и печатает параллельно поток чисел от 0 до 9, но дополнительно печатает информацию о каждом вызове инкремента:
UnaryOperator<Integer> incrementAndPrint = (i) -> {
System.out.println("increment " + i);
return i + 1;
};
Stream.iterate(0, incrementAndPrint)
.limit(10)
.parallel()
.forEach(i -> System.out.print(i + ", "));
5. Метод Stream.generate(Supplier s) позволяет создать бесконечный поток, элементы которого - результат многократного вызова переданного Supplier. Ограничить такой поток можно при помощи функций limit или takeWhile. Например, сгенерируем десять случайных идентификаторов.
Stream<String> uuids = Stream.generate(() -> UUID.randomUUID().toString())
.limit(10); К нашей задаче обработки почтовых индексов метод generate на первый взгляд подходит довольно хорошо. Идея в том, чтобы Supplier вычитывал следующую запись, а по условию takeWhile(r -> r != null) поток завершился. Так выглядит получившийся код, инициализация и обработка исключений опущены для краткости:
return Stream.generate(() -> reader.nextRow())
.takeWhile(r -> r != null)
.map(postIndexRowMapper::map); Простое выполнение данного кода происходит без ошибки и возвращает правильный результат. Однако стоит добавить вызов функции .parallel(), как программа завершается с исключением:
postIndexreaderImpl.readAllStreamHackingGenerate().toList(); //корректно
postIndexReaderImpl.readAllStreamHackingGenerate()
.parallel().toList(); //исключение com.linuxense.javadbf.DBFException
: com.linuxense.javadbf.DBFException
at java.base/jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at java.base/jdk.internal.reflect.NativeConstructorAccessorImpl
.newInstance(NativeConstructorAccessorImpl.java:77)
at java.base/jdk.internal.reflect.DelegatingConstructorAccessorImpl
.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.base/java.lang.reflect.Constructor.newInstanceWithCaller(Constructor.java:499)
...
Caused by: java.io.EOFException
at java.base/java.io.DataInputStream.readFully(DataInputStream.java:203)
at java.base/java.io.DataInputStream.readFully(DataInputStream.java:172)
at com.linuxense.javadbf.DBFReader.getFieldValue(DBFReader.java:415)
at com.linuxense.javadbf.DBFReader.nextRecord(DBFReader.java:345)
... 16 more Фактическая причина ошибки и аварийного завершения программы в том, что Supplier, который передан в generate и условие завершения в takeWhile не обязаны вызываться строго последовательно, не допуская ни единого "лишнего" вызова Supplier. При этом поведение библиотеки предполагает, что после того как метод readRow вернёт null, нужно завершить чтение данных, а при попытке будет выброшено исключение java.io.EOFException. Запретить клиентам нашего интерфейса применить параллельный поток невозможно. Кроме того, в будущих версиях JVM такой код может перестать работать и в последовательном (в противопоставление параллельному) режиме, если разработчики применят какие-то оптимизации.
Принципиальная причина ошибки в том, что нарушен контракт использования метода Stream.generate(). Javadoc этого метода:
@NotNull
@Contract("_->new")
public static <T> Stream<T> generate(
@NotNull java.util.function.Supplier<? extends T> s) Returns an infinite sequential unordered stream where each element is generated by the provided Supplier.
This is suitable for generating constant streams, streams of random elements, etc.
@Params: s – the Supplier of generated elements
@Returns: a new infinite sequential unordered Stream
Так или иначе, с помощью generate корректно и надёжно решить поставленную задачу не получилось, пробуем другие способы.
6. Получение потока из Iterator или Iterable. Между Iterator и Iterable разница минимальна и выбор зависит от того, может ли наш класс порождать итераторы (как коллекция) или же это скорее одноразовая операция. Главное назначение Iterable - использование в конструкции forEach. В случае когда нужен только итератор, Iterable добавит несколько неиспользуемых строк кода и может кого-то запутать.
Реализуем логику получения почтовых индексов в виде итератора.
Только не будем сразу преобразовывать строки к доменным объектам, чтобы код можно было переиспользовать для чтения произвольных DBF файлов.
Благодаря потокам, такое преобразование легко можно будет осуществить после, добавлением вызова метод .map(...), не усложняя код итератора.
public class DbfRowIterator implements Iterator<DBFRow> {
private final DBFReader reader;
boolean valueReady = false;
private DBFRow nextRow;
public DbfRowIterator(DBFReader reader) {
this.reader = reader;
}
@Override
public boolean hasNext() {
if (!valueReady) {
nextRow = reader.nextRow();
valueReady = true;
}
return nextRow != null;
}
@Override
public DBFRow next() {
if (!valueReady && !hasNext()) {
throw new NoSuchElementException();
} else {
valueReady = false;
DBFRow row = nextRow;
nextRow = null;
return row;
}
}
}
Следующие шаги - это цепочка Iterator -> Spliterator -> Stream. На вопрос как преобразовать Iterator к Stream cамый популярный ответ на Stackoverflow предлагает два немного отличающихся решения:
-
Iterator<String> sourceIterator = Arrays.asList("A", "B", "C").iterator(); Stream<String> targetStream = StreamSupport.stream( Spliterators.spliteratorUnknownSize(sourceIterator, Spliterator.ORDERED), false); -
Iterator<String> sourceIterator = Arrays.asList("A", "B", "C").iterator(); Iterable<String> iterable = () -> sourceIterator; Stream<String> targetStream = StreamSupport.stream(iterable.spliterator(), false);
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}А имея Spliterator получить Stream можно используя один из методов утилитного класса StreamSupport. В итоге получаем:
public Stream<PostIndex> readAllStreamNaive() {
try (BufferedInputStream bis = new BufferedInputStream(Files.newInputStream(indexFilePath));
DBFReader reader = new DBFReader(bis)) {
Iterator<DBFRow> dbfRowIterator = new DbfRowIterator(reader);
return StreamSupport.stream(
Spliterators.spliteratorUnknownSize(dbfRowIterator, 0), false)
.map(postIndexRowMapper::map);
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}Что же здесь происходит? Имея Iterator мы получаем Spliterator, но указываем, что никакой уточняющей информации об ограничениях, накладываемых на элементы внутри Iterator у нас нет. Можно было бы указать ORDERED или ORDERED | NONNULL | IMMUTABLE, но лучше сделать так же, как в Iterable и передать 0. По крайней мере, пока нет глубокого понимания, что из себя представляют все эти флаги. Создавая поток из Spliterator указываем параметр parallel = false. Это начальное значение флага, которое может быть изменено позже вызовами методов .parallel() или .sequential().
Кстати, после первой же терминальной операции на результирующем потоке код падает с исключением:
java.lang.IllegalArgumentException: this DBFReader is closed
at com.linuxense.javadbf.DBFReader.nextRecord(DBFReader.java:312)
at com.linuxense.javadbf.DBFReader.nextRow(DBFReader.java:404)
at com.hipravin.post.reader.dbf.DbfRowIterator.hasNext(DbfRowIterator.java:22)
at java.base/java.util.Iterator.forEachRemaining(Iterator.java:132)
at java.base/java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1845)
at java.base/java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:509)
at java.base/java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:499)
at java.base/java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:921)
at java.base/java.util.stream.ReduceOps$5.evaluateSequential(ReduceOps.java:258)
at java.base/java.util.stream.ReduceOps$5.evaluateSequential(ReduceOps.java:248)
at java.base/java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.base/java.util.stream.ReferencePipeline.count(ReferencePipeline.java:709)
Чтобы терминальная операция выполнилась успешно, необходимо, чтобы источник элементов потока в момент её выполнения был доступен. Когда поток получается из коллекции, достаточно, чтобы эта коллекция ещё была в памяти - это получается само собой благодаря сборщику мусора, который корректно отслеживает ссылки на объекты и "знает", что объект потока ссылается на, например, экземпляр ArrayList и не удалит его из кучи даже если других ссылок на этот экземпляр нет. Поток случайных чисел, получаемый методом new Random().ints() также не может каким-то образом "устареть" и сломаться из-за того, что источник элементов больше не активен.
Другое дело - сетевые, файловые ресурсы, обработка ответов от базы данных - всё то, что надо открывать, а потом закрывать. При создании потока мы открываем ресурс. В задаче почтовых индексов мы открываем файл на чтение, но закрыть его явно в блоке finally или неявно в try-with-resources мы не можем, потому что данные понадобятся позже. Прочитать файл до конца, а потом закрыть тоже не получится, так как это противоречит изначальной задумке использования потоков. Выход заключается в том, чтобы обязать клиента закрыть открытые ресурсы. Происходит это следующим образом:
- Одна из промежуточных операций при работе с потоками - onClose(Runnable closeHandler) позволяет добавить обработчик закрытия ресурсов после завершения работы с потоком.
- Интерфейс Stream расширяет интрерфейс AutoCloseable, соответственно все обработчики из onClose будут вызвани при вызове close() на потоке.
-
Потоки, которые требуют освобождения ресурсов, необходимо использовать в блоке try-with-resources:
try(Stream<PostIndex> postIndexStream = postIndexReader.readAll()) { long postIndicesCount = postIndexStream.count(); assertEquals(58444, postIndicesCount); }
Окончательный вариант получения потока почтовых индексов, вычитанных из файла, используя итератор:
public Stream<PostIndex> readAll() {
try {
BufferedInputStream bis = new BufferedInputStream(Files.newInputStream(indexFilePath));
DBFReader reader = new DBFReader(bis);
Iterator<DBFRow> dbfRowIterator = new DbfRowIterator(reader);
return StreamSupport.stream(
Spliterators.spliteratorUnknownSize(dbfRowIterator, 0), false)
.map(postIndexRowMapper::map)
.onClose(() -> closeQuietly(bis))
.onClose(() -> closeQuietly(reader));
} catch (IOException e) {
throw new UncheckedIOException(e);
}
} 7. Непосредственно реализовать интерфейс Spliterator. Сразу приведу готовый код, чтобы можно было визуально сопоставить код Iterator и Spliterator.
public class DbfRowSpliterator implements Spliterator<DBFRow> {
private final DBFReader reader;
public DbfRowSpliterator(DBFReader reader) {
this.reader = reader;
}
@Override
public boolean tryAdvance(Consumer<? super DBFRow> action) {
DBFRow nextRow = reader.nextRow();
if (nextRow != null) {
action.accept(nextRow);
return true;
}
return false;
}
@Override
public Spliterator<DBFRow> trySplit() {
return null;
}
@Override
public long estimateSize() {
return Long.MAX_VALUE;
}
@Override
public int characteristics() {
return 0;
}
}
public Stream<PostIndex> readAllStreamSpliterator() {
try {
BufferedInputStream bis = new BufferedInputStream(Files.newInputStream(indexFilePath));
DBFReader reader = new DBFReader(bis);
return StreamSupport.stream(new DbfRowSpliterator(reader), false)
.map(postIndexRowMapper::map)
.onClose(() -> closeQuietly(bis))
.onClose(() -> closeQuietly(reader));
} catch (IOException e) {
throw new UncheckedIOException(e);
}
} В интерфейсе Spliterator метод tryAdvance совмещает в себе пару hasNext/next из Iterator и его реализация в данном случае получается короче и понятней, так как не требует введения дополнительных флагов и вычитывания следующей записи заранее. Минус в том, что остальные методы выглядят так, словно разработчик забыл о них и оставил заглушки. Метод characteristics позволяет использовать более эффективные алгоритмы для выполнения отдельных операций с потоком, указав в виде битовой маски, что все элементы потока заведомо:
- DISTINCT - различны
- SORTED - отсортированы
- SIZED - количество элементов заранее известно
- SUBSIZED - количество элементов заранее известно также и после выполнения trySplit
- NONNULL - все элементы отличны от null
- IMMUTABLE - элементы не могут быть добавлены, удалены или заменены
- CONCURRENT - элементы могут быть добавлены, изменены или удалены в процессе перебора элементов из источника
- ORDERED - указывает, что для элементов определён порядок, которому следуют методы trySplit и forEachRemaining.
Методы trySplit и estimateSize даже не вызываются, если поток не параллельный. В итоге при реализации Spliterator, который функционально умеет то же, что и Iterator, существенное значение имеет только метод tryAdvance.
Потоки и коллекции
Пожалуй мы достаточно натерпелись, пытаясь представить информацию о почтовых индексах в виде потока. Теперь пришло время поработать готовым экземпляром потока и оценить преимущества по сравнению с другими способами работы с коллекциями. Для начала преобразуем поток в коллекцию. Поток - он, так сказать, одноразовый. Поэтому периодически без преобразования к коллекции не обойтись. Получается, как будто, бессмысленно - столько усилий потратить, чтобы вместо списка вернуть поток - и тут же преобразовать его обратно в список, потому что данные будут нужны многократно. Одна из причин так поступить - архитектура приложения: компоненты разрабатываются независимо и подход с потоками выбран как более гибкий, несмотря на то, что в другом компоненте на данный момент эта гибкость пока что не будет использоваться. В любом случа получение коллекций из потока - одна из самых частых операций, поэтому посмотрим на типовые примеры:
1. Преобразование потока в список (List), три способа:
List<PostIndex> indices = indicesStream.collect(Collectors.toList());
ArrayList<PostIndex> indices = indicesStream.collect(
Collectors.toCollection(ArrayList::new));
List<PostIndex> indices = indicesStream.toList(); //since java 16 В первом случае нет никаких гарантий о типе возвращаемого списка, хотя в текущей реализации всегда возвращается ArrayList. Второй способ позволяет указать тип коллекции. Третий способ доступен начиная с версии Java 16 и является предпочтительным. Во-первых, запись синтаксически короче. Во-вторых, в результирующем списке размер внутреннего массива равен количеству элементов (58444), в то время в ArrayList в первых двух случаях размен внутреннего массива чуть больше: 71140 (так происходит ввиду определённых различий внутренней реализации, которые трудно описать в двух словах). В-третьих, список, возвращаемый методом toList(), является неизменяемым, что является хорошей практикой программирования в общем. Если потребуется изменяемый список, то используем второй способ. Первый способ при этом самый распространённый, но IDE подсвечивает его применение, предлагая заменить на toList().
2. Преобразование потока в множество (Set):
Set<PostIndex> indicesSet = indicesStream.collect(Collectors.toSet());
Set<PostIndex> indicesSet = indicesStream.collect(
Collectors.toCollection(HashSet::new));
SortedSet<PostIndex> indicesSet = indicesStream.collect(
Collectors.toCollection(() -> new TreeSet<>(PostIndex.BY_INDEX_THEN_OTHER_COMPARATOR)));
assertThrows(ClassCastException.class, () -> {
indicesStream.collect(
Collectors.toCollection(() -> new TreeSet<>()));
}); Первый способ самый распространённый. Как и в случае со списком точный тип не специфицирован, но текущая реализация всегда использует HashSet. Можно указать тип явно, как сделано во втором и третьем примере, но нужно быть аккуратным с TreeSet - в случае, если Comparator не указан явно и тип элементов не реализует Comparable, то код компилируется, но падает с ClassCastException. А вот метода toSet() (как и toMap()) наподобие toList() в классе Stream в текущей версии нет (Java 17). Информацию почему можно найти в комментариях к соответствующему тикету JDK-8180352. Вкратце - toSet и toMap не вписываются в идеологию терминальных операций потока из-за того, что влекут за собой пост-обработку элементов. Коллекторы (Collector) - более подходящее место.
3. Преобразование потока в отображение (Map). Произвольный поток преобразовать к Map однозначным образом нельзя: нужно указать, как получить ключ, как получить значение, что делать в случае повторяющихся ключей. Самое частое, что под этим подразумевают - это выделение простого ключа (строка, число, дата или другой встроенный тип) и использование исходных объектов в виде значения. Обычно неявно предполагают, что все ключи различны ввиду специфики данных. Для почтовых индексов примером будет создание отображения с ключом шестизначного кода или имени (поля index и name). Гарантий уникальности ключей у нас нет, хотя данные предполагают, что индексы уникальны. Имена же заведомо не уникальны. Далее несколько примеров:
Map<String, PostIndex> indicesByIndex = indicesStream.collect(
Collectors.toMap(pi -> pi.index(), pi -> pi));
indicesStream.collect(
Collectors.toMap(pi -> pi.name(), pi -> pi)); //java.lang.IllegalStateException: Duplicate key
Map<String, PostIndex> indicesByName = indicesStream.collect(
Collectors.toMap(pi -> pi.name(), pi -> pi, (a, b) -> {
throw new IllegalStateException(
"Duplicate key %s (attempted merging values %s and %s)"
.formatted(a.name(), a.toString(), b.toString()));
})); //поведение по умолчанию, указанное явно
Map<String, PostIndex> indicesByName = indicesStream.collect(
Collectors.toMap(pi -> pi.name(), pi -> pi, (a, b) -> a)); //сохраняем первое значение
Map<String, PostIndex> indicesByName = indicesStream.collect(
Collectors.toMap(pi -> pi.name(), pi -> pi, (a, b) -> b)); //сохраняем последнее значение
На практике при использовании toMap всегда следует задуматься над качеством данных и поведением программы при обработке повторяющихся ключей. Ошибки в данных или программе могут привести к повторению значений, которые уникальны по бизнес логике. Первый вариант - следуя поведению по умолчанию, остановить обработку данных с исключением. Второй вариант - игнорировать повторяющиеся ключи, сохраняя первое или последнее значение. Однако гарантий по поводу "первое" и "последнее" в общем случае нет, в обоих случаях мы используем какое-то из двух, считая что разницы нет. Теоретически можно усложнить код и проверять совпадение значений при повторяющихся ключах и только если они отличаются выбрасывать ошибку, но на практике я с таким не сталкивался.
Ещё две практические задачи, связанные с отображением - сгруппировать объекты по ключу или посчитать их количество. Код короткий и понятный, без подводных камней:
Map<String, List<PostIndex>> groupedByRegion = indicesStream.collect(
Collectors.groupingBy(pi -> pi.region()));
Map<String, Long> countsByRegion = indicesStream
.map(PostIndex::region)
.collect(Collectors.toMap(r -> r, r -> 1L, Long::sum)); В данном контексте вспоминается классическая задача с собеседований - вывести содержимое Map в порядке, отсортированном по значению. Для нас аналогичную, но практически полезную задачу можно сформулировать так: найти пять регионов с самым большим количеством индексов. И вместо создания и сортировки отдельного массива или упорядоченного отображения с необычным компаратором решим её с помощью потоков. У меня получилось два варианта решения, которые отличаются в основном стилем написания кода:
//первый вариант
indicesStream
.map(PostIndex::region)
.collect(Collectors.toMap(r -> r, r -> 1L, Long::sum))
.entrySet().stream()
.sorted(Map.Entry.<String, Long>comparingByValue(Comparator.reverseOrder())
.thenComparing(Map.Entry::getKey))
.limit(5)
.forEach(e -> System.out.println(e.getKey() + " - " + e.getValue()));
//второй вариант
record RegionAndCount(String region, Long count) { }
Stream<RegionAndCount> regionAndCountStream = indicesStream
.map(PostIndex::region)
.collect(Collectors.toMap(r -> r, r -> 1L, Long::sum))
.entrySet().stream()
.map(e -> new RegionAndCount(e.getKey(), e.getValue()));
Comparator<RegionAndCount> byCountDescThenByRegionAsc =
Comparator.comparing(RegionAndCount::count, Comparator.reverseOrder())
.thenComparing(RegionAndCount::region);
List<RegionAndCount> regionsWithMostIndices = regionAndCountStream
.sorted(byCountDescThenByRegionAsc)
.limit(5)
.toList();
regionsWithMostIndices.forEach(rc -> System.out.println(rc.region + ": " + rc.count)); Первый вариант в одну строчку привлекает своей краткостью, но я больше склоняюсь ко второму. Он многословен, но более понятен и содержит контекст в виде имен промежуточных переменных, компараторов и использования специального класса вместо манипуляций с Map.Entry. Это как комментарии, только лучше. Кстати, объявление таких записей (record) с узкой областью определения непосредственно перед использованием является нормальной практикой и даже рекомендуется. Важно при сортировке отображения по значению обрабатывать ситуацию, когда значения совпадают. В данном случае если в двух регионах будет одинаковое количество индексов, то в первую очередь будет показан регион, значение которого лексикографически меньше.
Поиск почтовых индексов по префиксу
Вернёмся к исходной задаче. Напомню, что требуется реализовать поиск почтовых индексов, начинающихся с заданной подстроки. Это нужно, чтобы выдать короткий список подсказок для автозаполнения в соответствующем поле на сайте или в мобильном приложении. Уже реализована загрузка данных по индексам, результат представлен в виде потока экземпляров доменного объекта PostIndex. Также принято решение, что данные разумно хранить в памяти. И ещё мы рассмотрели основные способы получения разных коллекций из потока. Для завершения решения осталось выбрать наиболее подходящий тип данных и реализовать непосредственно алгоритм поиска.
Неэффективные решения, работающие медленнее, чем O(logN) рассматривать не буду. Решение "в лоб" - использовать отсортированный список, найти бинарным поиском позицию, на которой должен находиться префикс и пройти далее пока не превысим ограничение на длину результата или не встретим индекс, не удовлетворяющий префиксу. Напомню, что индексы у нас представлены строками, а не числами, поэтому "122555" < "123" < "123001" в соответствии с лексикографическим порядком. Ниже показан пример работы алгоритма. Значение "123" в отсортированном списке должно находиться перед "123001". Бинарный поиск находит эту позицию и нужно пройти дальше по списку, добавить значения "123001", "123002", "123004" в результирующий список, а потом остановиться на значении "124005". Ни одна строка, которая лексикографически больше "124005", не может начинаться с префикса "123".
...
122555
123 <- префикс
123001
123002
123004
124005 <- стоп
125007
... Реализация в императивном стиле:
@Override
public List<PostIndex> findByIndexStartingWith(String prefix, int limit) {
PostIndex stubPrefixPostIndex = new PostIndex(prefix, "", "", "", "", "", "");
int binarySearchResult = Collections.binarySearch(
indices, stubPrefixPostIndex, BY_INDEX_THEN_OTHER_COMPARATOR);
int fromPosition = binarySearchResult >= 0
? binarySearchResult
: -(binarySearchResult + 1);
int toPositionExclusive = Math.min(indices.size(), fromPosition + limit);
List<PostIndex> result = new ArrayList<>();
for (int i = fromPosition;
(i < toPositionExclusive) && indices.get(i).index().startsWith(prefix); i++) {
result.add(indices.get(i));
}
return result;
} Код выглядит довольно низкоуровневым, сложно сопоставить отдельные операции с бизнес логикой. Для начала приходится создавать несуществующий экземпляр класса PostIndex, чтобы передать его в binarySearch. Потом нужно обработать результат бинарного поиска, который может быть меньше нуля и равен (-(insertion point) - 1), если элемент не найден. Также в цикле приходится использовать двойное условие, что тоже уменьшает читаемость кода.
Реализация становится значительно проще, если использовать более подходящую структуру данных - TreeMap и работать с ней через интерфейс SortedMap. Ключом будет сам индекс, а значением - PostIndex. Метод SortedMap.tailMap(prefix) почти в одиночку решает всю задачу, возвращая подмножество, начиная с элемента, ближайшего к prefix. При этом новое отображение - это всего лишь "ссылка" (view), то есть копирования не происходит, а значит не требуется ни дополнительной памяти, ни ресурсов процессора. Использование потоков, а именно методов takeWhile и limit решают оставшуюся часть задачи.
private final SortedMap<String, PostIndex> byIndex;
...
public List<PostIndex> findByIndexStartingWithStreamImpl(String prefix, int limit) {
return byIndex.tailMap(prefix).values().stream()
.takeWhile(pi -> pi.index().startsWith(prefix))
.limit(limit)
.toList();
} Код действительно лаконичный, декларативный и последовательный. Можно утверждать, что это один из показательных примеров, как потоки улучшают код. Код без потоков с использованием SortedMap лучше, чем через список, но всё равно выглядит немного коряво из-за использования конструкции break:
public List<PostIndex> findByIndexStartingWithImperativeImpl(String prefix, int limit) {
List<PostIndex> result = new ArrayList<>();
Collection<PostIndex> tail = byIndex.tailMap(prefix).values();
for (PostIndex postIndex : tail) {
if (postIndex.index().startsWith(prefix) && result.size() < limit) {
result.add(postIndex);
} else {
break;
}
}
return result;
} На этом решение задачи автозаполнения для почтовых индексов закончено. Реализация соответствующего REST сервиса и клиентской части - тоже важная часть задачи, но не имеет отношения к потокам и уж слишком перегрузит статью.
Потоки и базы данных
Потоки также могут быть полезны при обработке результатов запросов к базам данных. Классы, которые раньше возвращали список элементов, получили аналогичные методы, возвращающие потоки. Вот несколько примеров:
- Spring JdbcTemplate. Добавлен метод queryForStream:
- javax.persistence.TypedQuery. Добавлен метод getResultStream. Реализация по умолчанию просто вызывает метод getResultList, но Hibernate честно реализует поведение потоков. Если копнуть вглубь реализации, обнаружим такие классы как ScrollableResultsIterator и StreamDecorator.
- Spring Data. Теперь методы, которые возвращали список теперь могут возвращать поток, даже без указания этого в имени или сигнатуре метода. Примеры из документации:
List<T> query(...);
Stream<T> queryForStream(...); List<X> getResultList();
Stream<X> getResultStream(); @Query("select u from User u")
Stream<User> findAllByCustomQueryAndStream();
Stream<User> readAllByFirstnameNotNull();
@Query("select u from User u")
Stream<User> streamAllPaged(Pageable pageable);Когда результат запроса к базе данных представлен в виде потока следует учитывать несколько важных дополнений по сравнению с привычным подходом, в котором результатом является список. Во-первых, при работе с потоком требуется активная транзакция, а это требует переноса аннотации @Transactional на один уровень выше в иерархии вызовов. Во-вторых, такие потоки требуют явного закрытия или применения конструкции try-with-resources, что заметно уменьшает читаемость кода. Допустим, что у нас есть компонент-репозиторий и компонент-сервис, работающие с почтовыми индексами, которые на этот раз хранятся в базе данных. Так выглядит код при работе со списками:
//PostIndexJpaRepository
@Query("select pi from PostIndexEntity pi where pi.index like :prefix% order by pi.index")
List<PostIndexEntity> findByIndexStartingWith(@Param("prefix") String prefix, Pageable pageable);
//PostServiceDbImpl
@Override
public List<PostIndexDto> searchIndexStartingWithListImpl(String indexPrefix, int limit) {
return postIndexJpaRepository.findByIndexStartingWith(indexPrefix, PageRequest.of(0, limit))
.stream()
.map(DtoMappers::fromEntity)
.toList();
} При переходе на Stream код меняется следующим образом:
//PostIndexJpaRepository
@Query("select pi from PostIndexEntity pi where pi.index like :prefix% order by pi.index")
Stream<PostIndexEntity> findByIndexStartingWith(@Param("prefix") String prefix, Pageable pageable);
//PostServiceDbImpl
@Override
@Transactional //если забыть, то org.springframework.dao.InvalidDataAccessApiUsageException
public List<PostIndexDto> searchIndexStartingWith(String indexPrefix, int limit) {
try (Stream<PostIndexEntity> indexEntityStream =
postIndexJpaRepository.findByIndexStartingWith(indexPrefix, PageRequest.of(0, limit))) {
return indexEntityStream.map(DtoMappers::fromEntity)
.toList();
}
} В отличие от предыдущих примеров, в которых потоки были призваны улучшить код, сделав его более гибким, понятным или кратким, в данном случае имеет место только усложнение кода синтаксически и семантически, а также немотивированное увеличение времени жизни транзакции. Теоретически на уровне сервиса могут собираться воедино ответы от разных баз данных и тогда простым добавлением @Transactional проблема бы не решилась.
При этом возможность улучшить производительность или снизить потребление памяти довольно сомнительна: паттерны использования баз данных предполагают, что вся условная выборка и, может быть, сортировка результатов запросов происходит на стороне базы данных. Кроме того, обычно количество записей в ответе мало - часто это одна запись или одна страница, ограниченная 10, 20, максимум 100 записями. На мой взгляд для таких сценариев списки подходят намного лучше.
Возможно, что при обработке больших объёмов данных для каких-то аналитических или фоновых задач можно применить потоки для ускорения обработки за счёт параллелизма. Сейчас под рукой нет подобной задачи, чтобы проверить.
Потоки и освобождение ресурсов (Stream#close)
В статье уже несколько раз в том или ином виде затрагивалась тема освобождения ресурсов после завершения работы с потоком. В одном случае мы сами открывали файл на чтение, в другом - библиотека для работы с базой данных использовала соединение из пула, инициировала транзакцию и открытие курсора. В обоих случаях мы имеем дело с каким-то внешним ресурсом, который в теории может быть сильно ограничен и если не задуматься о его корректном освобождении, то непременно рано или поздно случится переполнение памяти, исключение или бесконечное ожидание. Не столь болезненное проявление ошибок управления ресурсом - замедление работы программы или увеличение потребления памяти ввиду того, что ресурс всё-таки освобождается, но происходит это позже чем нужно, например, во время очередного цикла сборки мусора. Однако стоит признать, что зачастую проблематично воспроизвести проблему не удаётся: программа без явных вызовов close или блоков try-with-resources продолжает работать корректно и пропускная способность меняется в пределах погрешности измерений. Однако зная из опыта, как коварно и неожиданно может проявиться подобная проблема, я буду стоять на своём - внешними ресурсами нужно пользоваться корректно в любом случае.
Любой поток является экземпляром класса, реализующего интерфейс java.util.Stream, который расширяет интерфейс AutoCloseable. Простой и привычной практикой было бы любые классы, реализующие Closeable или AutoCloseable использовать только в конструкции try-finally или try-with-resources. Можно было бы настроить соответствующие подсказки от IDE или проверить код с помощью статического анализатора (например, Sonar), чтобы убедиться, что все ресурсы используются корректно. Но в реальности для потоков такой код был бы избыточным в большинстве случаев. Например, нужно в списке list найти самую длинную строку:
String longest = list.stream()
.max(comparing(String::length))
.orElse(null); То же самое, но следуя практике закрытия всех потоков без исключения:
String longest = null;
try (Stream<String> values = list.stream()) {
longest = values.max(comparing(String::length))
.orElse(null);
} Так никто не поступает, так не нужно поступать, и даже в документации класса AutoCloseable существует специальное указание: "... However, when using facilities such as java.util.stream.Stream that support both I/O-based and non-I/O-based forms, try-with-resources blocks are in general unnecessary when using non-I/O-based forms." То есть, если потоки не работают с какой-то формой ввода-вывода (например, сеть или файловая система), то использование конструкции try-with-resources "в общем ненужно". То есть точных и однозначных указаний как поступать в данном случае не существует. Нужно на основании документации и общих представлений понять, что из себя представляет конкретный экземпляр потока и решить, связан ли он с какими-то ресурсами, которые необходимо или желательно освободить.
В таком случае разработчики будут неизбежно игнорировать закрытие потоков, пока это не приводит к очевидным проблемам. Существует надежда на IDE, но на момент написания статьи подсказки о необходимости использовать try-with-resources для потоков в IDEA замечены только для Files.lines.
Почему бы просто не закрывать все ресурсы в момент выполнения терминальной операции на потоке? Разработчики hibernate даже реализовали такое поведение с помощью класса-обёртки над потоком (StreamDecorator<R> implements Stream<R>). Однако в его текущей реализации метод close будет вызван только при успешном выполнении терминальной операции. В случае возникновения исключения, или если вообще не вызвать терминальную операцию, метод close не будет выполнен. К слову, такой функционал в hibernate появился в версии 5.4, ссылка на тикет. Но поддержка спецификации JPA 2.2, в которой добавлен метод Query#getResultStream, началась с версии 5.3, и если сравнить графики выхода релизов, то получится, что три года пользуясь библиотекой hibernate нужно было использовать конструкцию try-with-resources, а теперь как будто необязательно (хотя всё ещё нужно). Существует также и практически официальный ответ от разработчиков Java на вопрос почему закрытие потоков не осуществляется в терминальных операциях автоматически. https://stackoverflow.com/questions/28813637/why-doesnt-java-close-stream-after-a-terminal-operation-is-issued В общем, потоки, связанные с какими-то ресурсами, это очень редкий и специфический случай, который легко обрабатывается конструкцией try-with-resource.
Возможно, я сгущаю краски по поводу важности освобождения ресурсов при использовании потоков. Если в приложении существует сценарий, когда выделяется соединение (Connection) с базой данных, но не закрывается, то оно не будет возвращено в пул никогда, и программа гарантированно перестанет работать со временем. Также встречались сценарии, когда не закрытые экземпляры apache HttpClient приводили к тому, что сетевые запросы переставали отправляться. Утечки памяти гарантированно приводят к переполнению памяти. Перезагрузки раз в неделю могут спасти, если проблема проявляется редко и не успевает исчерпать ресурс. Со временем приходится переходить на ежедневные рестарты.
Но что касается примеров, перечисленных в статье, обнаружить очевидные ошибки мне не удалось. Я проверил многократное (10_000) выполнение запросов в рамках одной транзакции, в разных транзакциях, с пулом соединений по умолчанию и с ограничением в одно соединение, но безрезультатно. Вернее, результат в том, что вызов метода AbstractScrollableResults#close не критичен в условиях, когда управление соединениями и транзакциями обеспечивается надёжными библиотеками. То, что какие-то регистры, связанные с PreparedStatement и ResultSet, не очищаются сразу, не влечёт за собой немедленных ошибок, потому что ещё есть закрытие транзакции.
И всё-таки OutOfMemory!
Пока я старательно сочинял оправдания неудачных экспериментов, я решил повторить попытку сломать программу тем же способом, но сильно ограничив доступную процессу память (-Xmx128m), а также увеличив количество записей в одном запросе с десяти до ста. В результате после 3000 итераций выполнение проограммы завершилось с ошибкой: java.lang.OutOfMemoryError: Java heap space. На сайте есть статья про OutOfMemoryError, если интересны детали исследования такой ошибки. Если вкратце, то добавляем параметр VM "-XX:+HeapDumpOnOutOfMemoryError", запускаем Eclipse Memory Analyzer Tool и изучаем отчёт:
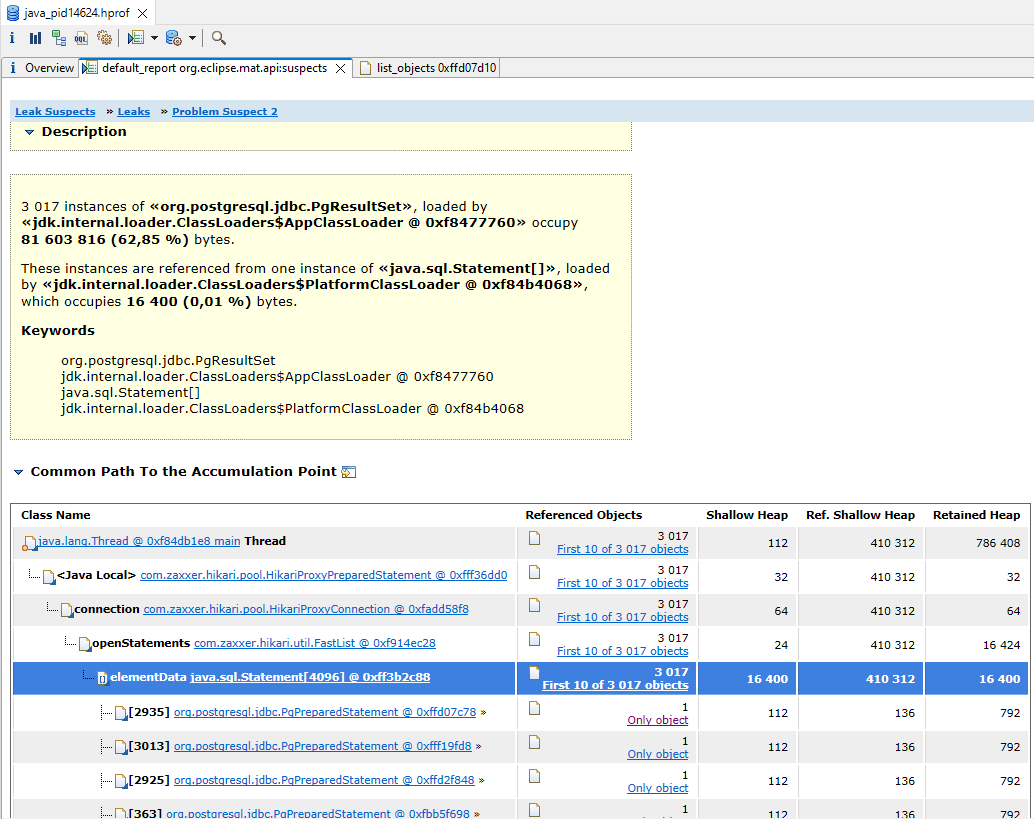
Видно, что большая часть памяти занята экземплярами класса «org.postgresql.jdbc.PgResultSet». В репозитории с примерами за тест отвечает класс NoCloseOomInSingleTransactionTestingRunner. Повторю ещё раз, что привело к ошибке:
-
Результат выполнения запроса к базе представлен в виде потока.
@Query("select pi from PostIndexEntity pi where pi.index like :prefix% order by pi.index") Stream<PostIndexEntity> findByIndexStartingWith(@Param("prefix") String prefix, Pageable pageable); -
В процессе обработки в рамках одной транзакции многократно выполняется запрос, но обработка потока завершается с исключением, которое игнорируется.
@Transactional public List<PostIndexEntity> searchTerminalNoCloseExceptionRepeated(String indexPrefix) { for (int i = 0; i < 10_000; i++) { try { postIndexJpaRepository.findByIndexStartingWith(indexPrefix, PageRequest.of(0, 100)) .peek(e -> {throw new RuntimeException("on purpose");}) .toList(); } catch (RuntimeException e) { } } return List.of(); } -
Если добавить блок try-with-resources, то переполнение памяти не происходит.
... try(Stream<PostIndexEntity> postIndexes = postIndexJpaRepository.findByIndexStartingWith(indexPrefix, PageRequest.of(0, 100))) { ...
Такой сценарий довольно специфичен, но не так уж фантастичен. Допустим, существует унаследованная (legacy) база данных из которой периодически фоновым процессом загружаются данные в новую систему. Ввиду сложной доменной модели и сложившейся традиции, загрузка происходит большими транзакциями: так лучше обеспечивается консистентность данных в процессе обновления. Часть данных низкого качества, типизация слабая. Например, в полях - перечислениях периодически появляются значения, которых там быть не должно. Либо они там есть давно и все к ним привыкли. Такие данные приводят к исключениям в процессе обработки результатов запроса, которые игнорируются, потому что требование к системе - загрузить как можно больше данных, а отдельные ошибки можно игнорировать. Например, если в реестре индексов есть несколько явных опечаток, то это не повод останавливать систему, пока ошибки не будут исправлены. Утечки памяти происходят постоянно, но только до завершения транзакции. Переполнение памяти может возникнуть при увеличении объема базы либо при ухудшении качества данных.
Files.lines
Не столь хитрый и сложный, но очень удобный добавленный вместе с потоками метод - Files.lines(path), который возвращает все строки текстового файла, не загружая их в память одновременно. Сколько раз вы встречали подобный код?
String line;
while ((line = reader.readLine()) != null) {
... Поиск на github комбинации while и readLine в категории Java выдаёт 4,227,711 совпадений. Теперь с использованием Files.lines весь этот код можно убрать и оставить только само тело блока while, то есть логику работы со строками, убрав повторение очевидных шагов чтения строк, пока не встретим null. Сравните решения задачи подсчёта количества не пустых строк в файле:
public long countLines(Path path) {
try(BufferedReader reader = Files.newBufferedReader(path, StandardCharsets.UTF_8)) {
long counter = 0;
String line;
while((line = reader.readLine()) != null) {
if(!line.isBlank()) {
counter++;
}
}
return counter;
} catch (IOException e) {
throw new UncheckedIOException(e);
}
} @Override
public long countLines(Path path) {
try (Stream<String> lines = Files.lines(path, StandardCharsets.UTF_8)) {
return lines.filter(s -> !s.isBlank()).count();
} catch (IOException e) {
throw new UncheckedIOException(e);
}
} Конечно, не менее удобно использовать метод Files.readAllLines, который заодно гарантирует освобождение файловых дескрипторов без необходимости явного использования блока try-with-resources. Но если Files.lines можно использовать всегда, то для Files.readAllLines нужно всегда держать в голове потенциальный размер файла.
На Github очень много примеров вызова Files.lines без закрытия потока:
- https://github.com/vitaliikrik/LabsSlovakia/blob/91de29f96dff7d04f3e5227e85dfd2ec02721d59/src/kry/edu/module4/FilesManagementTask.java
- https://github.com/eliftehcproedu/Lambda/blob/31fc488a64af5055a96244b607df23b0ae1a3946/_1_Lambda/Stream_Ornekler/Steram06Files.java
- https://github.com/pszczola4mk/algo/blob/989707a9cfa3ac5a9dd48b7755de73e1dc3280b4/src/main/test/pg/cui/spoj/MorganStringTests.java
- https://github.com/cihanypc/lambda/blob/fbf11deffe2b22d04ad89e3647f67b4899eeb617/src/Lambda_06.java
- https://github.com/dbs-leipzig/gradoop/blob/23f8d5cb5f6ad5cbb6d1aa1cf329c959d6cc1782/gradoop-flink/src/main/java/org/gradoop/flink/model/impl/operators/matching/common/statistics/GraphStatisticsLocalFSReader.java
Согласно довольно старой статье на javacodegeeks, неправильное использование Files.lines при большом количестве повторений (100_000 в примере) приводит к исчерпанию файловых дескрипторов и ошибке: "Caused by: java.nio.file.FileSystemException: ...: Too many open files in system" Самостоятельно на версии JRE 17.0.5 под управлением Windows 10 воспроизвести такую ошибку мне не удалось. Возможно, это связано изменениями в JVM. Взяв простую задачу подсчёта строк в файле и сравнив разные способы реализации, я достиг замедления работы программы приблизительно в полтора раза на очень коротких файлах (4 байта), если не закрывать поток. С файлами даже 1кб разница производительности в пределах погрешности. В репозитории за соответствующие эксперименты отвечает модуль file-lines. Для запуска тестов нужно выполнить класс BenchmarkRunner. Тест также показывает, что производительность чтения файла с помощью Files.lines, BufferedReader и Files.readAllLines совпадает.
Накладные расходы и производительность
Оптимизация приложений на Java обычно не является первостепенной задачей. Код должен быть поддерживаемым, безопасным, разумно гибким, максимально точно соответствовать бизнес требованиям. Оптимизацию, хоть это и спорный подход, откладывают на потом. На практике достаточно использовать подходящие структуры данных и правильные алгоритмы, не пытаясь сэкономить каждый возможный байт или такт процессора. При необходимости существенно улучшить производительность применяются архитектурные решения: кэширование, репликация.
Тем не менее, если совсем не задумываться о производительности, то за счёт "мелочей" можно получить пропускную способность, например, в два раза меньше возможной. Например, использовать объекты там, где можно обойтись примитивами. Использовать synchronized там, где можно обойтись без синхронизации или же использовать потокобезопасныю коллекцию, операцию CAS (Compare and Set). Наиболее заметное влияние на производительность подобные нюансы оказывают при манипуляциях с числами, коллекциями, массивами, но без запросов к внешним сервисам или базам данных.
Можно предположить, что старый добрый цикл for или while для алгоритмических задач будет быстрее, а потоки привнесут заметные накладные расходы за счёт сложности внутренней реализации ReferencePipeline и вероятного использования дополнительных вспомогательных объектов. Но так ли это? Возьмём простейшую задачу - найти сумму чисел от 1 до 100 миллинов, без формул. Базовая производительность - простой цикл for с примитивами. Оценим на сколько замедлится программа, если применить поток примитивов, поток объектов, цикл с BigInteger, операции flatMap, mapMulti, filter. Можете сделать предположения перед тем, как смотреть результаты.
public static long sumPrimitiveStream(long sumToInclusive) {
return LongStream.rangeClosed(0, sumToInclusive).sum();
}
public static long sumBoxedStream(long sumToInclusive) {
return LongStream.rangeClosed(0, sumToInclusive).boxed()
.reduce(0L, Long::sum);
}
public static long sumPrimitiveCycle(long sumToInclusive) {
long sum = 0;
for (long l = 0; l <= sumToInclusive; l++) {
sum += l;
}
return sum;
}
public static long sumBoxedCycle(long sumToInclusive) {
Long sum = 0L;
for (Long l = 0L; l <= sumToInclusive; l++) {
sum += l;
}
return sum;
}
public static long sumPrimitiveFlatMap(long sumToInclusive) {
return LongStream.rangeClosed(0, sumToInclusive)
.flatMap(l -> LongStream.of(l)) //useless operation to measure flatmap overhead
.sum();
}
public static long sumPrimitiveMapMulti(long sumToInclusive) {
return LongStream.rangeClosed(0, sumToInclusive)
.mapMulti((l, c) -> c.accept(l)) //useless operation to measure mapmulti overhead
.sum();
}
public static long sumAtomicLong(long sumToInclusive) {
AtomicLong sum = new AtomicLong(0L);
for (long l = 0L; l <= sumToInclusive; l++) {
sum.addAndGet(l);
}
return sum.get();
}
public static long sumBigInteger(long sumToInclusive) {
BigInteger sum = BigInteger.ZERO;
for (long l = 0L; l <= sumToInclusive; l++) {
sum = sum.add(BigInteger.valueOf(l));
}
return sum.longValueExact();
}
public static long sumPrimitiveCycleWithIf(long sumToInclusive) {
long sum = 0;
for (long l = 0; l <= sumToInclusive; l++) {
if((l & 1) == 1) {
sum += l;
}
}
return sum;
}
public static long sumPrimitiveStreamWithFilter(long sumToInclusive) {
return LongStream.rangeClosed(0, sumToInclusive)
.filter(l -> (l & 1) == 1)
.sum();
} Далее результаты запуска теста на домашнем ноутбуке. Отличия в пределах погрешности обсуждать не стоит, а вот разница в 5-10 раз и более представляет определённый интерес. Если вы не работали с mapMulti, то это аналог flatMap, который может быть в определённых сценариях удобнее синтаксически (хотя обычно сильно не удобнее), а главное снижает накладные расходы при малом количестве элементов в flatMap-потоке. Появился в Java 16.
| Benchmark | Throughput (ops/s) | Error (+-ops/s) | Slowdown (times) |
|---|---|---|---|
| sumPrimitiveStream | 32,616 | 1,055 | 1 |
| sumPrimitiveCycle | 32,859 | 1,880 | x1 |
| sumPrimitiveMapMulti | 32,177 | 4,770 | x1 |
| sumAtomicLong | 1,869 | 0,068 | x17 |
| sumBoxedCycle | 1,296 | 0,080 | x25 |
| sumBoxedStream | 0,879 | 0,162 | x37 |
| sumPrimitiveFlatMap | 0,736 | 0,024 | x44 |
| sumBigInteger | 0,360 | 0,083 | x91 | Последние два сценария сравниваются больше между собой, чем с остальными: |
| sumPrimitiveStreamWithFilter | 15,891 | 3,083 | 1 |
| sumPrimitiveCycleWithIf | 11,757 | 1,774 | x1.3 |
Результаты данного сравнения достаточно условны, потому что функции не являются строго равнозначными решениями одной и той же задачи. Но всё же они развеивают опасения по поводу накладных расходов на использование потоков. Потоки хорошо оптимизированы и не проигрывают простому циклу. Выборка только нечётных чисел с помощью filter выполнилась даже немного быстрее, чем через if. Если программа выполняет большое количество арифметических операций, опасаться стоит в первую очередь ненужного преобразования примитива к объекту (boxing). Использовать BigInteger тоже не стоит повсеместно, только чтобы застраховаться от целочисленного переполнения, так как вычисления могут замедлиться на два порядка. Также стоит аккуратно пользоваться flatMap, если исходный поток большого размера, а "подпоток", наоборот, состоит из пары элементов. В этом случае можно воспользоваться нововведением Java 16 - методом Stream#mapMulti. Для корпоративных приложений, манипулирующих сложными доменными объектами, накладные расходы от потоков по сравнению с императивным подходом если и есть, то незначительны.
Предлагаю немного отвлечься от теории и решить небольшую практическую задачу.
В этой статье таблица выше была получена из текстового вывода:
BenchmarkConfig.bench_sumPrimitiveStream thrpt 5 32,616 ± 1,055 ops/s
BenchmarkConfig.bench_sumAtomicLong thrpt 5 1,869 ± 0,068 ops/s
BenchmarkConfig.bench_sumBigInteger thrpt 5 0,360 ± 0,083 ops/s
BenchmarkConfig.bench_sumBoxedCycle thrpt 5 1,296 ± 0,080 ops/s
Предполагая, что входные данные являются одной строкой, напишите код, добавляющий теги tr и td, а также убирающий лишние столбцы. Ожидаемый результат работы программы:
<tr><td>sumPrimitiveStream</td><td>32,616</td><td>1,055</td></tr>
<tr><td>sumAtomicLong</td><td>1,869</td><td>0,068</td></tr>
<tr><td>sumBigInteger</td><td>0,360</td><td>0,083</td></tr>
<tr><td>sumBoxedCycle</td><td>1,296</td><td>0,080</td></tr> Далее решение, которое получилось у меня. Кажется разумнее часть логики перенести в отдельную функцию, без использования потоков и функционального стиля, чем пытаться всё решение как-то уместить в одно монструозное выражение.
public static String toHtmlTableBody(String rawTextReport) {
Pattern reportLinePattern = Pattern.compile(
"^\\s*BenchmarkConfig.bench_(\\S+)\\s+thrpt\\s+\\d+\\s+(\\S+)\\s+±\\s+(\\S+)\\s+ops/s\\s*$");
return sampleReport.lines()
.map(line -> wrapGroups(line, reportLinePattern, "<td>", "</td>"))
.map(line -> "<tr>" + line + "</tr>")
.collect(Collectors.joining("\n"));
}
private static CharSequence wrapGroups(String text, Pattern pattern, String prepend, String append) {
StringBuilder result = new StringBuilder();
Matcher matcher = pattern.matcher(text);
if(!matcher.find()) {
return "";
}
for (int i = 1; i <= matcher.groupCount(); i++) {
result.append(prepend)
.append(matcher.group(i))
.append(append);
}
return result;
} Лямбда-выражение или ссылка на метод?
При использовании потоков через строчку приходится использовать простые предикаты или функции, которые можно сформулировать в двух почти идентичных формах:
в виде лямбда-выражения или в виде ссылки на метод:
//лямбда-выражения
.filter(v -> v instanceof MyType)
.map(v -> (MyType) v)
//то же самое, но ссылки на метод
.filter(MyType.class::isInstance)
.map (MyType.class::cast)
Я предлагаю следовать совету, который даёт Джошуа Блох в книге "Java. Эффективное программирование": чаще всего принимать предложение среды разработки заменить лямбда выражение ссылкой на метод, но в отдельных случаях делать исключение, если лямбда-выражение более краткое. Например, service.execute(() -> action()) и service.execute(GoshThisClassNamelsHumongous::action) Или вместо Function.identity() использовать лямбда-эквивалент x -> x.
Параллельные потоки
Читая статьи различных авторов, прихожу к единственному на сто процентов рабочему совету по поводу параллельных потоков: не используйте их. Не столь категоричное заявление звучит так: даже не пытайтесь применять параллельные потоки, пока не обладаете уверенностью в том, что это принесёт пользу во всех сценариях, в первую очередь в условиях эксплуатационной нагрузки (продуктив), но главное не приведёт к ошибкам и сохранит корректное поведение программы.
Переключить потоки на параллельное исполнение исключительно просто: либо добавить вызов .parallel(), либо вместо .stream() использовать .parallelStream(), если источником является коллекция. Лучший результат, которого можно добиться таким образом - увеличение производительности кратно количеству ядер процессора. Столь удачно обстоятельства складываются редко, хотя при написании кода, как правило, от параллелизма ожидается ускорение хотя бы в два раза. С практической точки зрения выигрыш даже десяти процентов за счёт одной строчки кода выглядит очень привлекательно.
Каким образом поток распределяет вычисления по разным нитям исполнения? Сердце параллелизма - операция Spliterator#trySplit(), которая должна поделить Spilterator пополам. Если это невозможно, то разделить нужно максимально равнозначно. Исходный поток делится на две части, потом каждая часть делится снова и в какой-то момент вычисление переходит на последовательную обработку в одной из нитей встроенного ForkJoinPool. Момент, на котором деление останавливается, определяется эвристически:
//java.util.stream.AbstractTask
//на моей машине LEAF_TARGET = 28
private static final int LEAF_TARGET = ForkJoinPool.getCommonPoolParallelism() << 2;
public static long suggestTargetSize(long sizeEstimate) {
long est = sizeEstimate / getLeafTarget(); //1024 / 28 = 36
return est > 0L ? est : 1L;
}
...
//AbstractTask.compute
long sizeThreshold = getTargetSize(sizeEstimate);
...
while (sizeEstimate > sizeThreshold && (ls = rs.trySplit()) != null) {
...
task.leftChild = leftChild = task.makeChild(ls);
task.rightChild = rightChild = task.makeChild(rs);
... То есть деление не происходит до тех пор, пока trySplit не вернёт null. Поток из 1024 элементов по факту обрабатывается частями по 36 элементов. Эти детали реализации и параметры эвристик не находятся под контролем разработчика, но они нужны для понимания. Понимания того факта, что следует довериться JVM и его магии, либо отказаться от параллельных потоков.
Проверим, что получится, если добавить .parallel() в какие-нибудь примеры. В качестве подопытных кроликов выступят различные способы сложения целых чисел, которые мы сравнивали чуть ранее с целью изучения возможных накладных расходов потоков. Результат вычисления верный, программа отработала корректно во всех случаях. Поэтому остаётся оценить прирост производительности.
| Benchmark | Throughput (ops/s) | Error (+-ops/s) | Throughput gain (times) | Сумма примитивов |
|---|---|---|---|
| rangeClosed(0, sumToInclusive).sum() | 31,991 | 4,831 | 1 |
| rangeClosed(0, sumToInclusive).parallel().sum() | 136,491 | 36,017 | x4.26 | Сумма объектов |
| ...boxed().reduce(0L, Long::sum) | 0,946 | 0,048 | 1 |
| ...boxed().parallel().reduce(0L, Long::sum) | 1,427 | 0,179 | x1.5 | Сумма примитивов с лишним flatMap внутри |
| ...flatMap(l -> LongStream.of(l)).sum() | 0,735 | 0,055 | 1 |
| ...flatMap(l -> LongStream.of(l)).parallel().sum() | 0,796 | 0,030 | x1.08 |
Три эксперимента и три совершенно разных результата: увеличение в 4 раза (4 ядра), увеличение в полтора раза и незначительное улучшение в пределах погрешности. Такое поведение намекает на один из способов использования параллельных потоков - попробовать, измерить и оставить или вернуть как было в зависимости от результата. Положительный результат не гарантирован, потому что измерение на машине разработчика и тестовых данных может дать диаметрально противоположные результаты в сравнении с показателями под эксплуатационной нагрузкой в продуктиве.
Я пока оставлю без точного объяснения результаты этого эксперимента. Возможно, метод trySplit делит поток слишком неравномерно, возможно flatMap сбрасывает характеристики SIZED/SUBSIZED и внутренние оптимизации перестают работать. Может быть, затраты на объединение результатов из отдельных потоков (thread) сводят на нет весь выигрыш от использования всех ядер процессора. Если есть возможность или необходимость углубляться в детали поведения многопоточного приложения, то не надёжнее ли воспользоваться инструментами из пакета java.util.concurrent?
Заключение
В данной статье мы прошлись "галопом по потокам", сравнив отдельные примеры их использования как со стороны поставщика данных, так и со стороны потребителя. Изучили сценарии работы с потоками, связанными с внешними ресурсами, такими как файлы или базы данных и те проблемы, которые возникают, если игнорировать закрытие потоков. Буквально одним глазком взглянули на параллельные потоки, оценили как пользу так и риски их использования.