Elasticsearch + Kibana (но без Logstash)
При изучении состояния продакшен сервера и поиска возможных ошибок и их причин используются логи приложения. Всё, что в коде выглядит как log.info/debug/error/trace, потом чаще всего попадает в один или несколько файлов, размер которых может достигать нескольких гигабайт в сутки, если слишком увлекаться логированием, например, всех SQL запросов и параметров (show_sql=true). Чтобы такие файлы не блокировали приложение, логи ротируются: файл обрезается до, скажем, 1гб, архивируется, а приложение продолжает писать логи в старый файл, но уже пустой. Такие файлы скапливаются и получают добавку к имени: .1.log.gz, .2.log.gz и так далее до заданного лимита по количеству или сроку давности.
Что же делать если нужно исследовать ошибку, случившуюся два-три дня назад?
Опцию открывать файлы по одному в редакторе я не рассматриваю, ведь за неделю может легко накопиться десять или сотня таких файлов.
На помощь приходит команда grep/zgrep: пишем незамысловатые команды наподобие
zgrep -i "ArrayIndexOutOfBounds" /data/logs/application/*202003*log*.gz
Как читатель мог разумно предположить, это устаревший и неэффективный подход, и использование полтонекстового индексного поиска упростило бы задачу в разы. Такой поиск реализован в проверенной временем библиотеке Apache Lucene, на основе которой построена поисковая система Elasticsearch. Общение c Elasticsearch происходит при помощи REST интерфейса, поэтому для пользователя нужна система, предоставляющая браузерный интерфейс. Это Kibana. Остаётся только автоматизированно парсить логи и всю новую информацию сохранять в Elasticsearch. Эту задачу решает Logstash.
Честно признаюсь, что с классическим, хорошо настроенным стеком ELK (Elasticsearch + Logstash + Kibana) мне работать не довелось. В современных облачных PAAS сервисах он настроен и включен по умолчанию. Но в сложных и старых системах это может быть не просто. В попытках изучить и применить ELK стек я получил интересный опыт и наработки, о которых здесь и расскажу.
Сам стек и его компоненты лучше всего описаны на официальном сайте: logz.io ELK Stack. Краткое содержание:
-
Logstash определяет местоположение логов, формат данных и адрес запущенного elasticsearch сервера
#/etc/logstash/conf.d/apache-01.conf ... path => "/home/ubuntu/apache-daily-access.log" ... match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ] ... hosts => ["localhost:9200"] -
Elasticsearch - NoSQL база данных с огромным количеством возможностей для поиска и агрегации данных.
Запросы к нему выполняются посредством REST api, пример простого поискового запроса ниже:
GET /_search { "query": { "query_string" : { "query" : "(new york city) OR (big apple)", "default_field" : "content" } } } - Kibana - браузерный интерфейс. Что-то вроде навороченного клиента к базе данных, только из будущего. Скриншот взят с Logz.io.

Elasticsearch и Kibana особенно настраивать не нужно - на локальной машине прекрасно работает конфигурация по умолчанию.
А вот с Logstash у меня возникали трудности - логи были хитро зархивированы и в целом не приспособлены к загрузке в elasticsearch построчно.
Выглядели они приблизительно следующим образом:
thread 001: =======СТАРТ========
thread 001: пользователь: hipravin@company.com
thread 001: проверка доступа: АДМИН,ДЕВЕЛОПЕР
thread 002: =======СТАРТ========
thread 001: вычитываем какие-то данные из базы...
thread 001: данные вычитались успешно
thread 001: обновление данных: значение1, значение2
thread 001: успешно
thread 001: ======ФИНИШ==========
Распарсить подобные логи на Java несложно, а вот как и можно ли вообще сделать такое в logstash, я не уверен. Поэтому я оставил logstash до лучших времен и подключился к elasticsearch напрямую. Существует проект Spring Data Elasticsearch, который упрощает задачу, но на текущий момент он не поддерживает elasticsearch последней версии, поэтому я использую готовый REST клиент, являющийся частью elasticsearch. При загрузке данных такими блоками можно кроме самого текста выделять важные параметры: время обработки, права доступа, успешно или ошибка, какие-то существенные данные для анализа. После этого по данным параметрам можно будет осуществлять поиск и агрегацию, строить красивые графики и диаграммы. Да, эти параметры приходится доставать из лога с помощью регулярных выражений. Зато не нужно никак менять работающее приложение, достаточно научиться скачивать логи с продакшен сервера.
В качестве примера я проведу небольшое исследование производительности работы с файлами. Программа будет создавать новый файл, записывать в него данные и вычитывать, измеряя затраченное время, а потом удалять файл. Информация о каждом полном цикле будет сохраняться в одной записи в elasticsearch, что в его терминологии называется документом. Всё это будет происходить в многопоточном режиме и количество потоков будет увеличиваться со временем. После чего я покажу базовые способы работы c этими данными в Kibana.
Код тут. Нужно установить Kibana и Elasticsearch 7 версии.
Для этого достаточно распаковать архивы и запустить. Вот как это выглядит у меня:
C:\dev\ELK\kibana-7.5.2-windows-x86_64\bin\kibana.bat
C:\dev\ELK\elasticsearch-7.5.2\bin\elasticsearch.bat
Теперь нужно научиться сохранять данные в elasticsearch. Он принимает данные в формате JSON, поэтому определим DTO класс:
public class WriteReadBenchmarkResult {
private String id;
private String threadName;
private int nThreads;
private long writeMillis;
private long readMillis;
private long fileSizeBytes;
private boolean failed = false;
private String errorMessage = "";
@JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd'T'HH:mm:ssZ");
private OffsetDateTime timestamp = OffsetDateTime.now();
//...getters, setters
Обращаться к elasticsearch будем с помощью High level REST client.
Создаём экземпляр клиента с настройками по умолчанию:
@Bean
public RestHighLevelClient client() {
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(
AuthScope.ANY, new UsernamePasswordCredentials("elastic", "changeme"));
RestClientBuilder builder = RestClient.builder(new HttpHost("127.0.0.1", 9200, "http"))
.setHttpClientConfigCallback(httpClientBuilder -> httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider));
RestHighLevelClient client = new RestHighLevelClient(builder);
return client;
}
for (WriteReadBenchmarkResult writeReadBenchmarkResult : batch) {
IndexRequest indexSingleRequest = new IndexRequest("samples-writrateread");
indexSingleRequest.id(writeReadBenchmarkResult.getId());
indexSingleRequest.source(mapper.writeValueAsString(writeReadBenchmarkResult), XContentType.JSON);
bulkRequest.add(indexSingleRequest);
}
BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
Теперь запустим тест, чтобы загрузить данные для анализа. Код в FileWriteReadRandomTaskIT, он довольно длинный, но ничего примечательного. Просто записываем в файл около 30 мегабайт, вычитываем и удаляем. Повторяем операцию 300 раз, а потом увеличиваем количество потоков на 1 и всё по новой. В тестовом запуске получилось пройти от 1 до 29 потоков за пару часов. Теперь переходим к изучению этой информации в Kibana.
Сначала нужно указать на тот индекс, который мы использовали, создав index pattern. Например, по ссылке http://localhost:5601/app/kibana#/management/kibana/index_pattern?_g=(). Либо в левой панели самый нижний значок - настройки. На шаге два (Step 2 of 2: Configure settings) выбираем timestamp, чтобы все наши данные имели временную метку, всё остальное происходит по умолчанию само. А именно: Kibana определяет набор полей и их типы. Например, поле readMillis - число, а значит его можно сравнивать, суммировать, находить максимумы и минимумы.
Я не показываю детально работу с интерфейсом Kibana, думаю для этого эффективнее всего установить и начать нажимать на все кнопки подряд, а также посмотреть пару самых простых сценариев на Youtube. Первое время я пользовался только текстовым поиском, а когда немного освоился, то начал пробовать фильтры, диаграммы и графики.
Итак, поиск. В терминах Kibana - Discover. Всегда нужно указать временные рамки. Пустой запрос означает все данные, простой текст означает индексный поиск по текстовым полям, а указание полей позволяет точно искать записи ("nThreads:8" - всё, что запускалось в 8 потоков). Посмотрим все операции и медленные чтения.
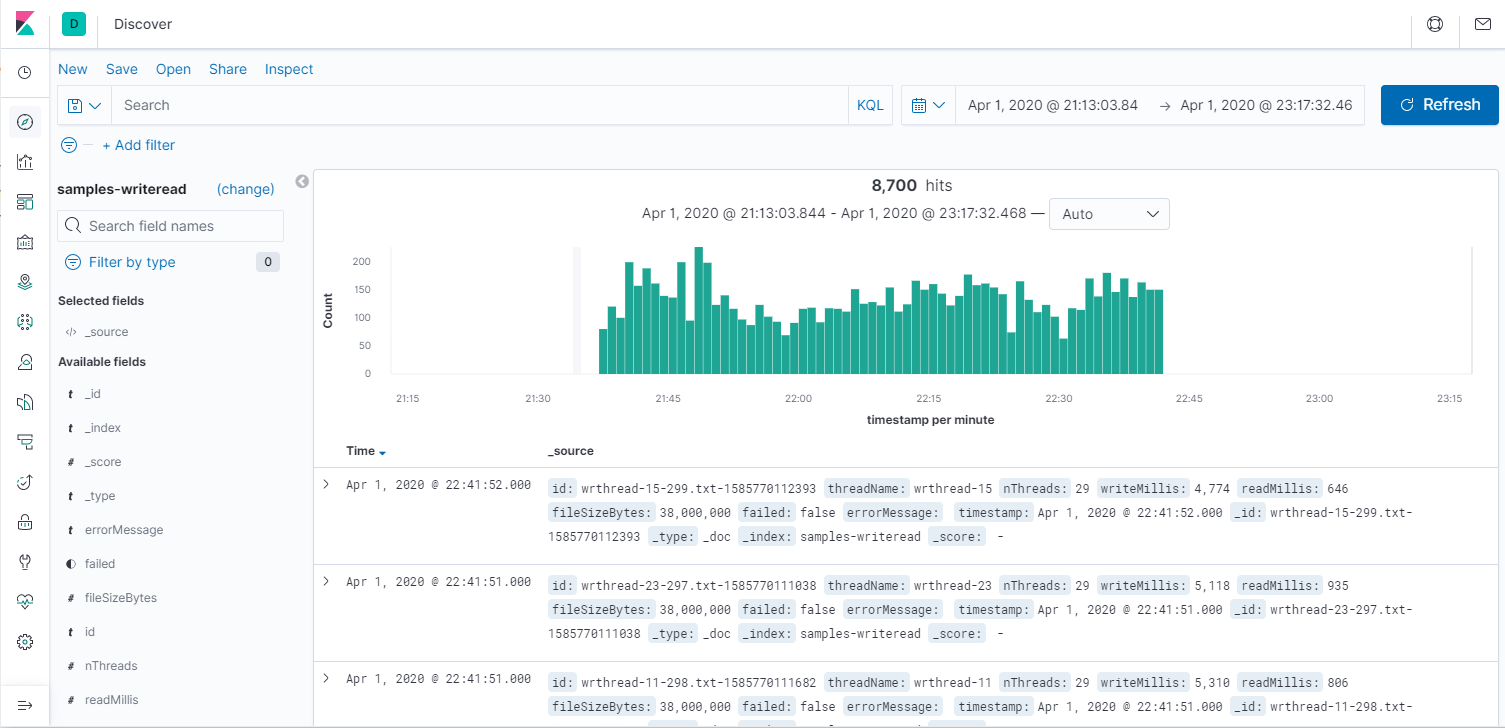
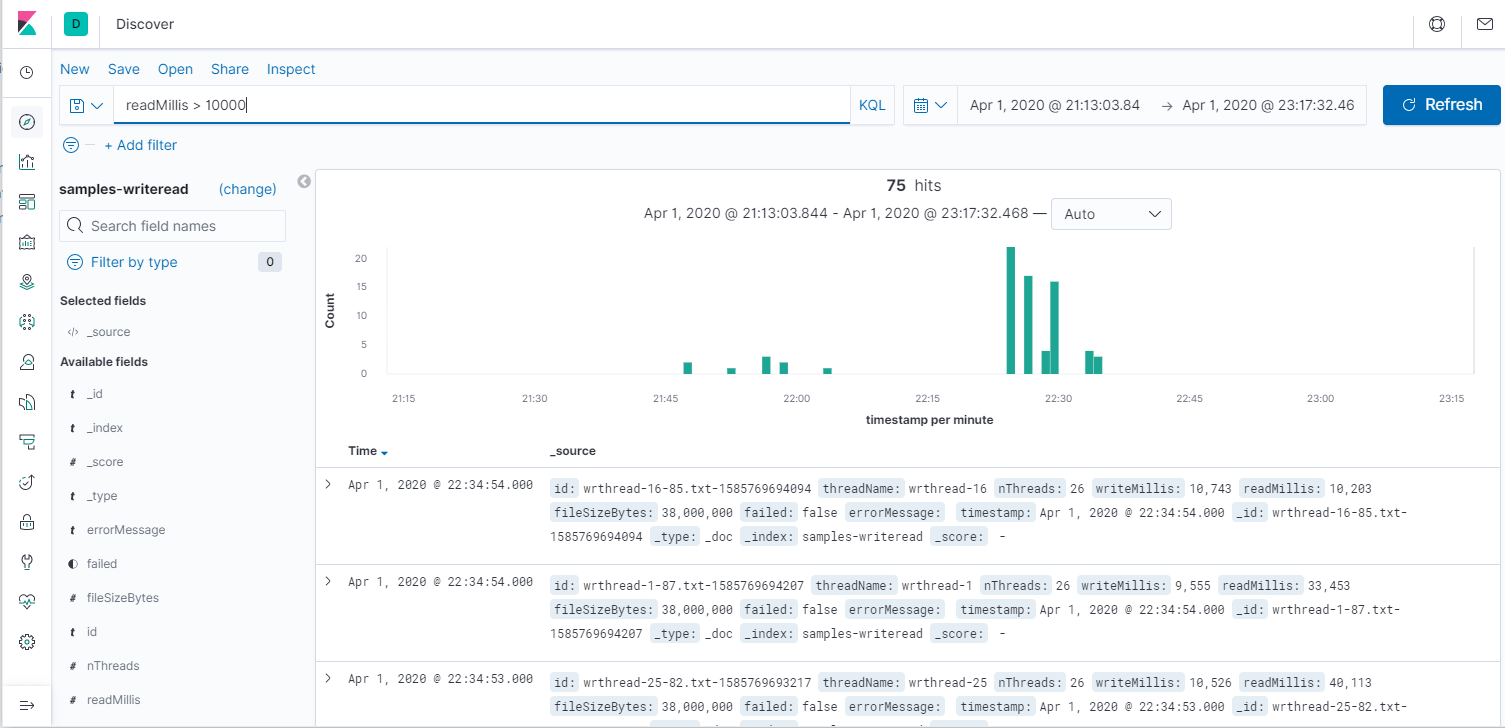
По сравнению в анализом данных командой grep, это уже космос. Давайте теперь посмотрим средние значения на графике. Для этого идём в Visualization -> Lines. Ось Х - Date histogram, то есть агрегация за промежуток времени: секунда, минута, день. Ось Y - Average/Min/Max/Count и и прочее. Первый график за всё время, второй - его начало (от 1 до 10 потоков.) На графике среднее время чтения и записи за 30 секунд, а также количество потоков, но я не смог его масштабировать, поэтому приходится наводить мышкой и на скриншотах не видно. Третий график - Count, показывает пропускную способность системы.
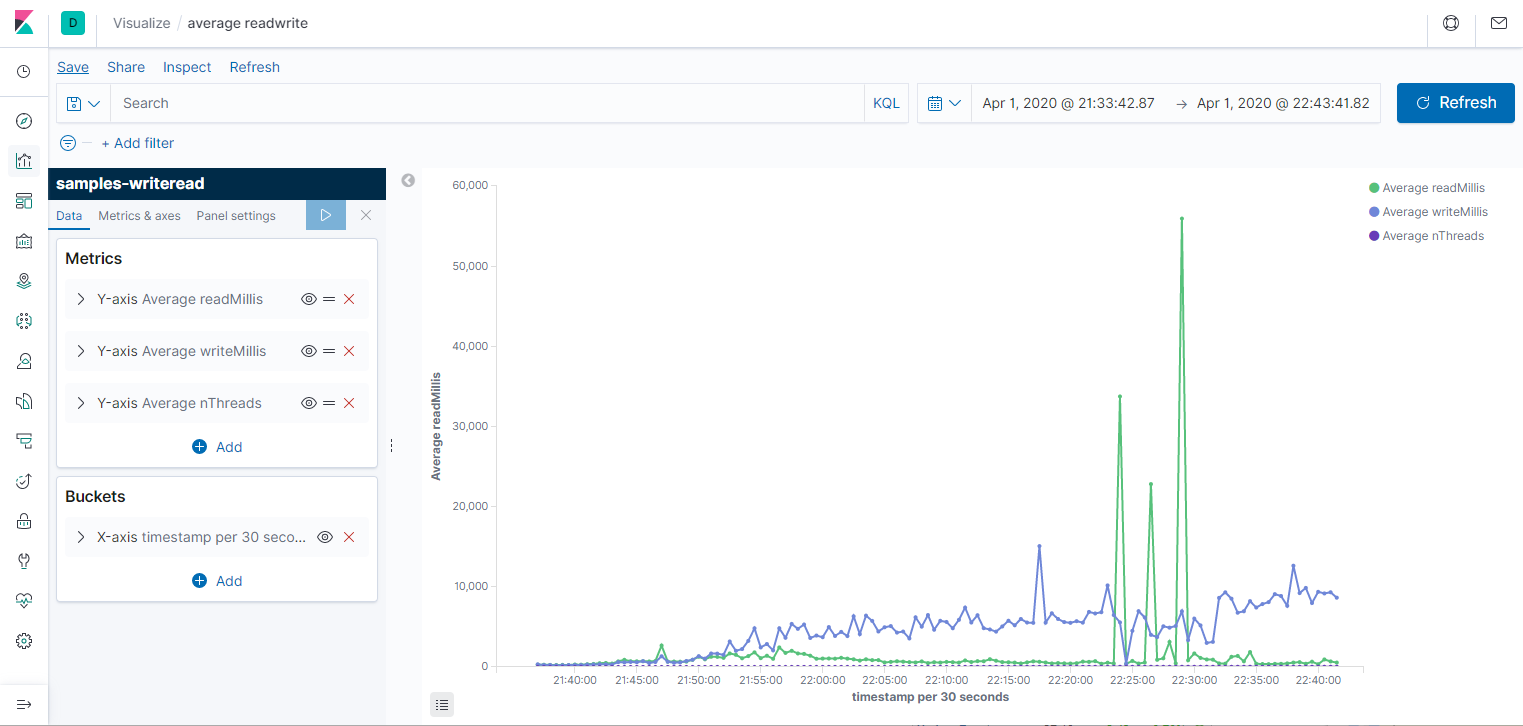
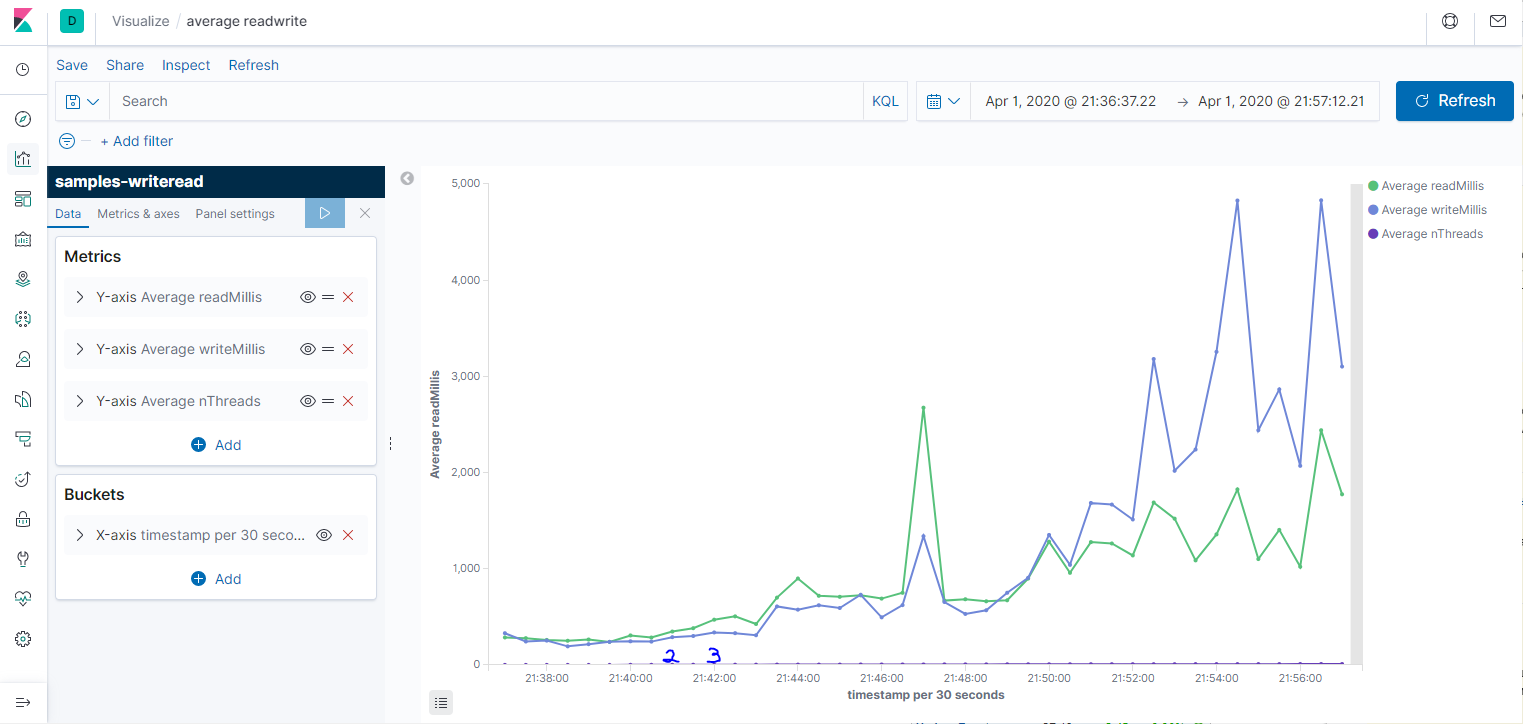
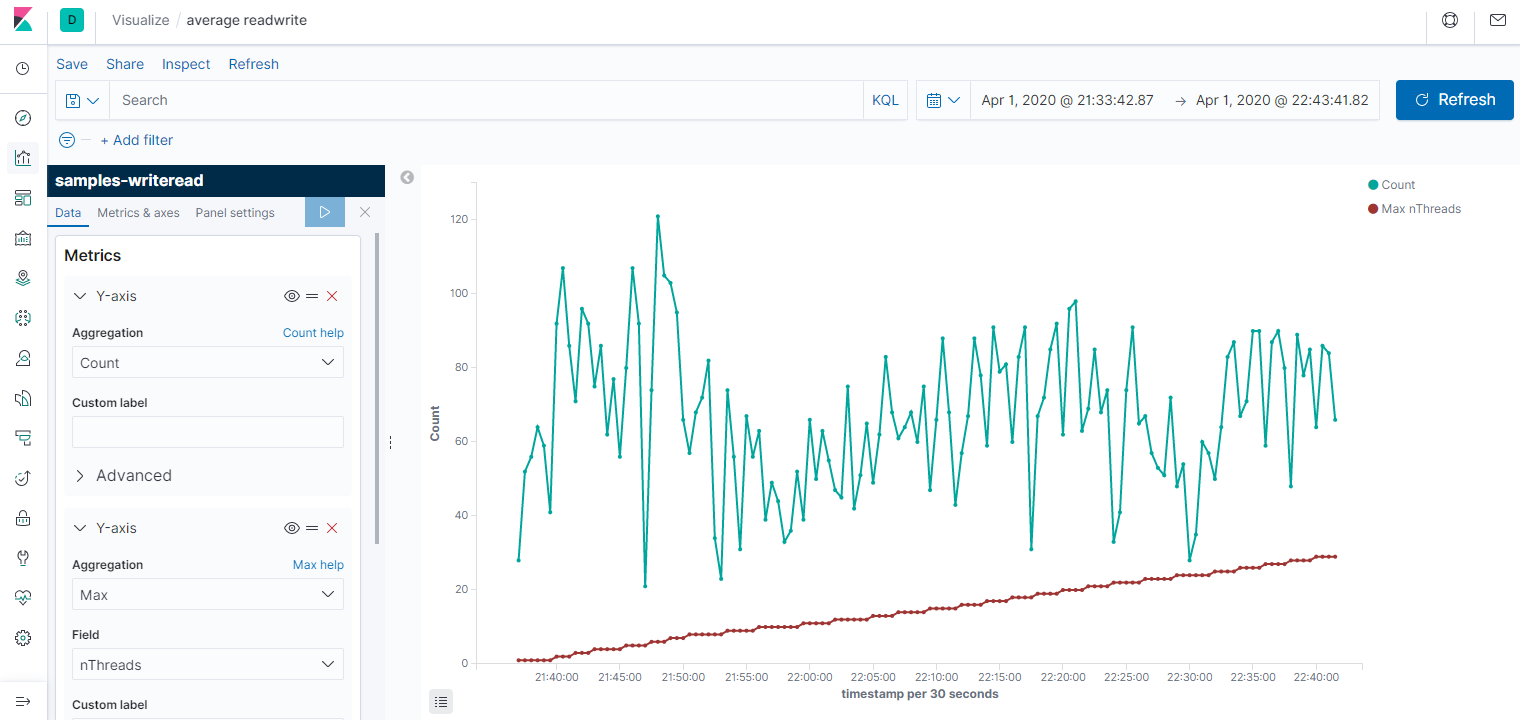
Делаю несколько выводов: во-первых, параметры недостаточно стабильны, чтобы им можно было серьёзно доверять. Во-вторых, с количеством потоков заметно растёт время записи и чтения. Время записи в среднем растёт сильнее. В третьих, при большом количестве потоков происходили очень неприятные пики до 170 секунд на чтение (если смотреть max, а не average). Возможно, ноутбук нагрузился какой-то запланированной работой в это время. Третий график вообще намекает на то, что степень параллелизма никак не влияет на пропускную способность.
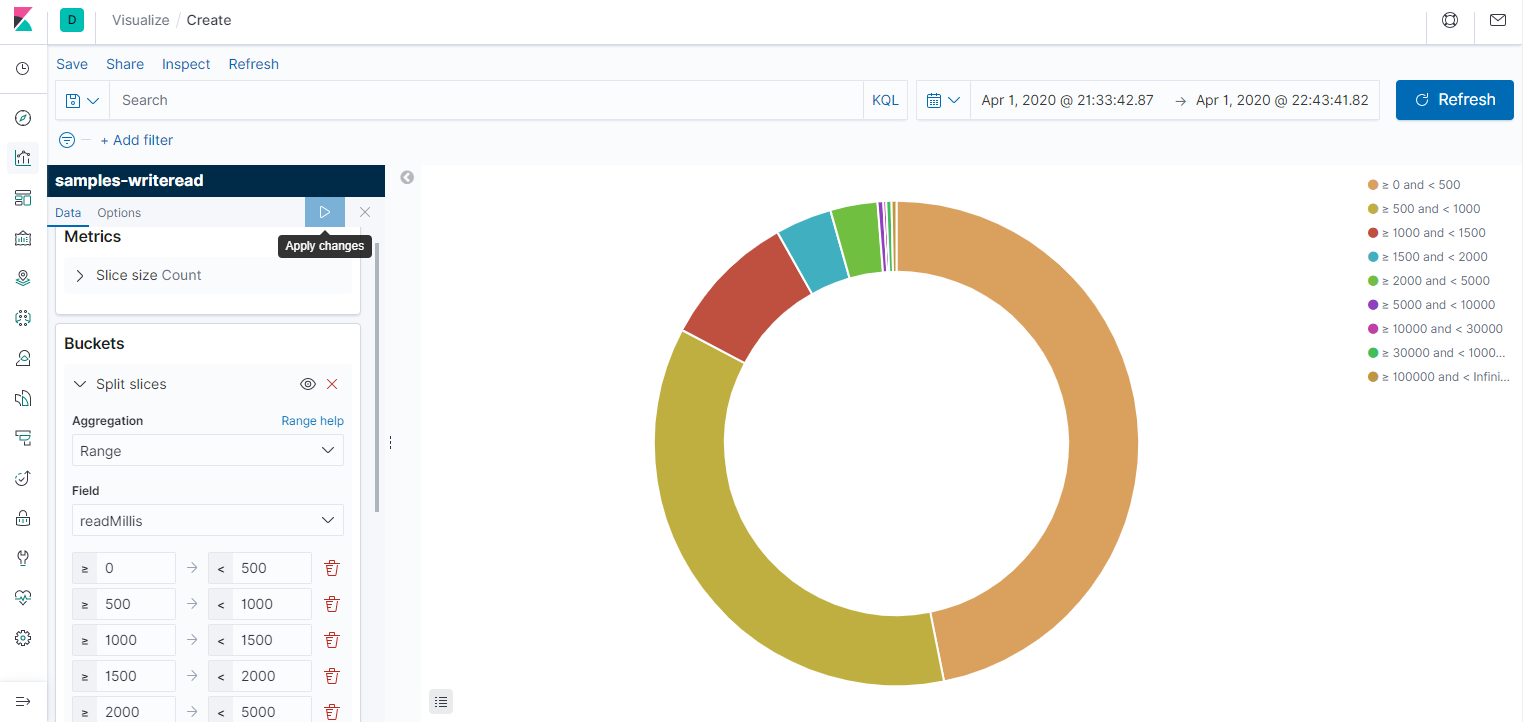
Результат ожидаемый. Если бы вместо жёсткого диска производилась работа с сетью, особенно с источником, который отвечает долго, но размер ответа небольшой, то пропускная способность росла бы почти линейно хоть до 100 потоков. Хотя результатом может стать DDOS источника данных. Думаю, ускорение можно было бы получить, если бы вместо одного жёсткого диска работа бы велась с несколькими. Так или иначе, цель - знакомство с elasticsearch и kibana, а такое мини-исследование производится просто ради спортивного интереса. Напоследок покажу диаграмму типа Pie, просто она мне нравится. Видно, что большинство чтений укладывается в секунду, а из них половина - в полсекунды.
Заключение
В первую очередь, я думаю, elasticsearch + kibana в таком использовании будут полезны тем, кто часто использует команду grep по однотипным логам. Обычно это старые системы, в которых нет времени или необходимости использовать готовые полнофункциональные решения, где всё уже интегрировано и настроено. Второе применение - это произвести более глубокий анализ данных, в особенности, логов, минимальными усилиями.